


Automatic speech recognition (ASR) is now an essential part of our lives in the form of various AI-enabled solutions. Some of the reliable speech-enabled solutions that we use on a daily basis include dictation software, voice assistants like Alexa, Siri, or Google Home, live captioning tools on YouTube, speech-to-text (STT) devices that translate lectures or doctors' notes, and other similar technologies.
But do we really understand what goes into training such extensive speech recognition models that understand your command of your native language and accent as well? It needs an unbiased and extensive speech dataset!
In this article, we will look into different types of speech datasets for different types of ASR applications, but before that, let us look into the basics of ASR.
Automatic Speech Recognition aka ASR

Automatic Speech Recognition (ASR) is a technology that allows users to interact or communicate with machines using their natural language. ASR allows the user to speak to the computer interface in the most sophisticated way that resembles natural human conversation, rather than punching keys on the keyboard.
You may have realized while calling a bank service provider that they also use speech recognition and you can directly speak to the Interactive Voice Response (IVR), whereas in the beginning you have to press the appropriate keys based on the IVR menu. But in most of the cases, you might have observed that they design the speech-enabled IVR menu in such a way that it asks you to reply in particular words. If you are not familiar with the IVR, here is how it is programmed to commands: If you want to check your balance, please say, "Check my balance.” In this way, it is suggesting the user to respond or ask in a particular series of words, and if the user asks the same thing in a different words, the system might not be able to handle the request. This type of conversation is called “Directed Dialogues Conversation”
Another ASR product we use in our daily lives that is far more sophisticated than direct dialogue conversation is mobile voice assistants or smart home devices like Alexa or Siri. The use of these devices is not limited to specific words or sentences, but rather mimics natural human conversation. For such devices to work at scale and assist with human-like conversation, natural language processing is an integral part of them. This type of conversation is referred to as “Natural Conversation”.
Despite the devices' 96 to 99% claimed accuracy, this accuracy is currently only possible under ideal circumstances. You must have realized your voice assistants do not perform well in a noisy environment compared to silent ones.

Speech Recognition Dataset for ASR
Similar to any other AI or ML model, a speech recognition model also needs a structured dataset for training and understanding of the user’s particular language. To train ASR models for any language, we need to feed them huge amounts of transcribed audio or speech data. To answer the question, "What is a speech recognition dataset?” We can say it is a collection of human-voiced speech or audio files, as well as their transcription. Transcription means a time-coded written format of whatever is being spoken in that audio file, along with some specific labels like noise, speaker id, music, etc. This audio file and transcription data are fed to a speech recognition model to train it in that specific language.
Libri-Light , one of the best English-language ASR models, is trained on 60 thousand speech hours, which is equivalent to 7 years of speech. This volume can vary based on language, model, and complexity. Preparing a speech dataset for your ASR or NLP model can be complex sometimes, so you need to be sure about your requirements and decide the technicality of the speech data. Many times, our clients are not sure about all the technical aspects and feasibility of speech data collection. FutureBeeAI can help in the case of defining requirements and collecting speech datasets.
Now, once we have a clear requirement on how much speech data is needed, the question comes is that from where to source it? The first option can be open-source speech data available on the internet that we can use following all compliances. But it is very difficult to find a huge amount of transcribed speech data specific to our requirements on the internet. Another option is to create a custom speech dataset based on specific needs.
You can also explore the FutureBeeAI datastore for 500+ ready-to-use transcribed speech datasets in more than 40+ languages. Speech dataset is a very subjective requirement that varies depending on the type of speech recognition model and stage of development. Based on that, there are various types of speech dataset requests we receive on a regular basis. Let’s explore each one of them in detail.
Types of Speech Dataset
As mentioned, companies dealing with speech recognition and natural language processing require different types of speech datasets, so if we want to briefly understand different types of speech datasets, then it will be as follows:
- Scripted speech dataset
- Scripted monologue speech dataset
- Scenario based speech dataset
- Spontaneous conversational speech dataset
- General conversation speech dataset
- Industry specific call center speech dataset

Each of these audio datasets has its own features, pros, and cons. Each one of these is being used for a specific type of use case, but the overall objective is to train speech and language models. Let’s deep dive into each type of speech dataset.
Scripted Speech Dataset
While creating a scripted planned speech dataset, we are restricting users to record specific types of sentences or content. Our goal here is to record these sentences by different profiles of speakers based on gender, native language, accent, age, and demographic. In any custom speech dataset collection, we provide all these details, along with some other details like date, format, sample rate, bit depth, noise level, etc., as metadata that serve a significant role in any speech model development.
We can further divide the planned speech dataset into two parts: the scripted speech dataset and the scenario-based speech dataset.
Scripted Monologue Speech Dataset
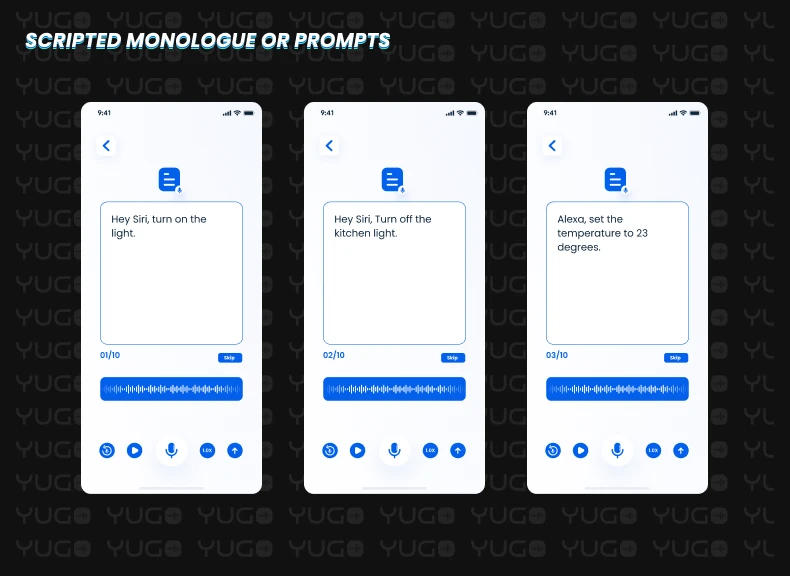
We often refer to this type of speech dataset as "scripted monologue," "prompt recording," "sentence recording," or "voice commands." To collect a scripted speech dataset, we first prepare the sentences that we need to record. Once we have all the sentences in xlsx format, we upload that to our Yugo speech data collection mobile application.
The Yugo mobile application allows us to onboard our global crowd community based on language, demographic, gender, and age requirements. We can also fix different technical features like sample rates, bit depth, and file format based on requirements. The speaker will read the sentence on the screen and record it in his or her natural voice. All these recordings, along with sentences in text, will prepare our speech corpus for that language.
In many cases, this type of dataset will include wake-word recordings, command recordings, or both. For example:
Hey Siri, turn on the light.
Hey Siri, Turn off the kitchen light.
Alexa, set
the temperature to 23 degrees.
Features
In the Scripted Speech dataset, we are not much
concerned with what is being said, and that’s why we are restricting users to record specific sentences
based on our research on the most common types of sentences being used by the actual users in real life. In
this type of dataset, we are more concerned with how any particular sentence is being said. We are
more interested in pronunciations, accents, and user profiles.
Pros
As we are recording only pre-scripted sentences in it, if
the dataset has been created with a large number of speakers, then such a dataset can be a very good source
to train the voice assistant model on different pronunciations of our specific target words.
Cons
If the script is not well researched or contains some
language-specific errors, it may cause some trouble. Our process of getting reviews from our native language
expert always works in this case.
Because we want people to record in specific scripted sentences only which they may or may not be used to, we may lose their natural speaking pattern in the process. We lose natural pauses, filler words, or mispronunciations that can occur when the actual user uses our speech product.
Scenario Based Speech Dataset
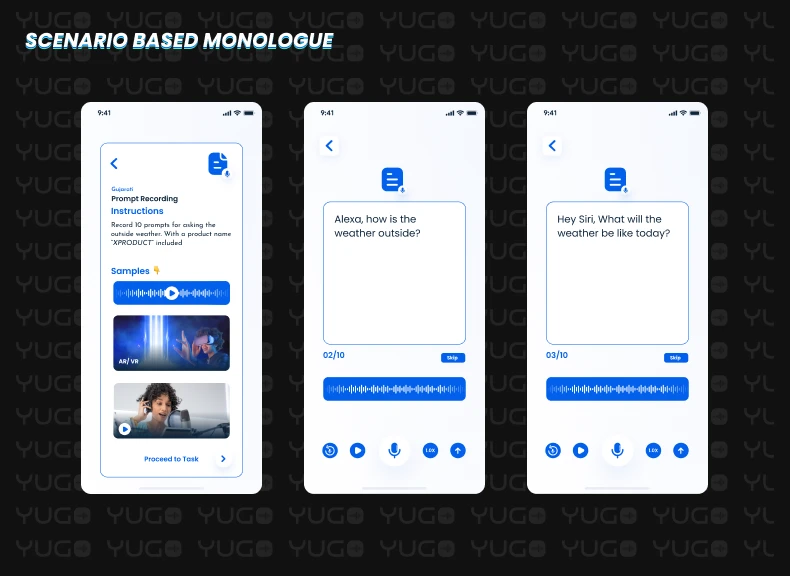
This type of dataset is very similar to a scripted speech dataset; the only difference is that we are not pre-scripting the entire sentence that needs to be recorded. Rather, we suggest that the recorder come up with a command as per his or her understanding of any specific scenario.
In this case, the user will see a suggestion on his or her Yugo mobile app screen like: “Record a command for asking the outside weather.” A large number of community users will submit a variety of commands requesting the same thing.
Alexa, how is the weather outside?
Alexa, tell me something about today’s weather.
Hey Siri, What will the weather be like today?
Hey Siri, Is it raining outside?
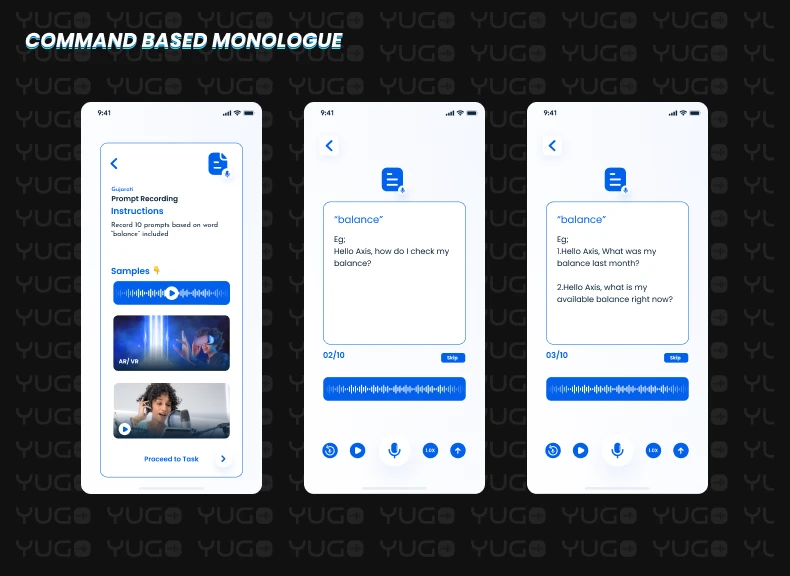
In another type of scenario, we give the user a word and ask him or her to come up with a command or prompt containing that word. This approach can be useful when creating industry- or domain-specific voice assistants.
In this case, the recorder will see a word on the Yugo app screen like "balance,” and the user will create different types of commands containing that particular word for that particular domain.
Hello Axis, how do I check my balance?
Hello Axis, What was my balance last month?
Hello Axis, what is my available balance right now?
Features
As we are not restricting the user to recording a
specific sentence, the user will come up with a variety of commands and prompts for that specific scenario.
When we need a large spectrum of data on how specific things can be asked or said, we can use this approach.
In this type of dataset, we are focusing on both what is being said and how it is being said.
Pros
This type of speech dataset can be helpful when we want to
train our voice assistant model on a variety of commands that can be asked in real life.
When we need to understand how the actual user will interact with our speech solution, we can choose this approach.
Cons
When we force the user to come up with a unique command
each time, sometimes we get data that might not be useful in real life. A user might come up with a command
that is so complex that the actual user might not use it in real life.
In this type of dataset, even after onboarding a large number of people, the recording of any particular command might not be available in various accents and user profiles. Unlike in a scripted speech dataset, in a scenario-based speech database, for each command, we have a comparatively low volume of data across all variables. That means we might need more volume for extensive training.
Spontaneous Conversational Speech Dataset
As the name indicates, in this dataset we record conversations between two or more people, not only scripted prompts or commands. These conversations can be scenario-based or general, but they will always be free-flowing and spontaneous.
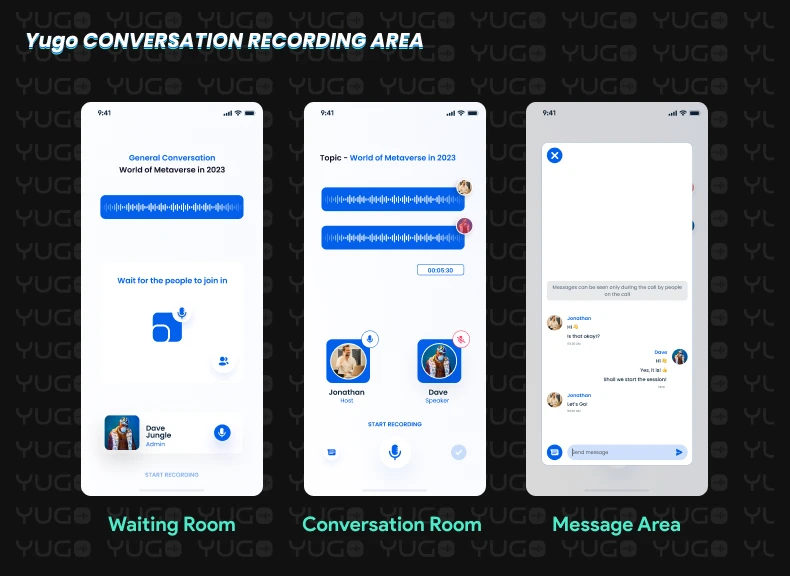
We here at FutureBeeAI have collected a huge amount of spontaneous conversations through our Yugo mobile app, which allows two users to join remotely and record the conversations seamlessly. At the backend, it facilitates us with separate and combined channels of audio files along with the user profile and required metadata like topic, subtopic, age, gender, country, accents, etc. Yugo also allows you to select and maintain technical features such as bit depth, sample rate, and file format before recording.
Let’s explore each type of spontaneous conversation speech dataset.
General Conversation Speech Dataset
This type of speech dataset contains audio conversations between two or more people on any general or random topic. It could be discussing daily life, hobbies, vacations, exams, games, and so on. It is like having a phone call with your friend or family and recording it.
In some cases, depending on the specific use case, these topics can be given, and users can be directed to record conversations revolving around that specific topic. Although it cannot be scripted and should be a spontaneous, free-flowing conversation,
S1: Hello Jay, How are you doing?
S2. I am doing well, Prakash. How about
you?
S1: I am good too. By the way, I want to ask you about the game you were talking about last night.
Which was that?
S2: I was talking about free fire. Have you checked that?
S1: Actually, I forgot
the name, so I thought I should ask you over the phone.
Features
Such a natural flow of recordings can be a rich source
of information about how actual users talk. In real human-to-human conversation, there are so many hidden
features, like the fact that they speak with many pre-assumptions in mind, they can switch to different
topics, and there may be various background features like noise or music, which can be labeled and used in
creating a robust and extensive speech model.
Pros
This type of dataset can be used to train speech models to
understand the context and flow of real-life conversations. It can help understand natural speech that
contains filler words, errors, and overlapping when both speakers speak at the same time.
Cons
Due to the many variables included in the speech dataset,
it is very crucial that we define our requirements very clearly.
A training model for such an unpredictable conversation with a large number of variables is complex and requires a large amount of data!
Gather Structured Speech Datasets at Scale!
Browse with over 10+ use cases and 50+ languages on the go! Samples are available!

Industry-Specific Call Center Speech Dataset
In any industry, customer service is a very crucial aspect, and now all industries want to adopt a more sophisticated approach than directed dialogue conversations. Every organization wants to build an AI-enabled speech model that talks to customers in a natural way.
For that, we need a real-life call center speech dataset, but in many cases, acquiring a real-life call center recording containing a conversation between a customer and a customer executive can be complex due to the PII(Personally Identifiable Information). It needs to pass through a process of anonymization even after following all compliance measures. FutureBeeAI can help you with this as well.
Apart from this, we also create synthetic call center conversations in a Yugo application. We onboard two users: one will play the role of customer, and the other will play the role of customer executive. They are trained to record realistic conversations in which the user poses a realistic problem and the customer service representative solves it throughout the recording. In such cases, we also make sure that each recording is intended to cover a specific topic and contains all the elements of a call center conversation to make sure it sounds realistic.
One such conversation might go something like this:
S1: Hello, Welcome to Future Bee AI Bank. How may I help you today?
S2:
Hello, I need
some help with my bank account.
S1: Sure, ma’am. I would love to help you with that. Tell me more
about it.
S2: Actually, I was trying to check my balance but was unable to do so. So can you check
and tell me my balance?
S1: Sure, ma’am, but before that, I have to confirm a few details with
you.
Features
Although the flow of a call center conversation is not
as random as that of a general conversation, the entire conversation contains various building blocks such
as welcome talk, problem/query statement, understanding, authentication, problem solving, feedback, and so
on.
We make sure that these synthetic call center conversations contain each of these conversation elements. Apart from that, such conversations can be of positive, negative, or neutral sentiments as well to make the dataset more diverse and unbiased.
Pro
Synthetic call center conversations can be comparatively
easy to acquire due to the low compliance involved. The personal information in such recordings is also
dummy, so related concerns can be avoided.
Accurately curated data can be very useful to train any industry-specific customer service speech model.
Cons
The main concern that arises while acquiring such
synthetic call center recordings is quality. Proper training of both users about their respective roles is
very crucial. Review at every stage of data collection by an expert quality analyst can raise the quality
bar even higher. So the entire process needs even more careful attention.
Immense research is needed about the kinds of questions customers come up with for that particular industry to make sure we create a dataset that replicates real life.
To train a model to work in real life, we need a huge amount of data to make sure the model is trained on every scenario.
FutureBeeAI’s Speech Dataset Pool
FutureBeeAI can assist you with all your speech dataset requirements for ASR and NLP models. We have created solutions for each stage of data collection.
FutureBeeAI help businesses identify the optimal dataset requirements. It is frequently a try-and-test method. We have a pre-labeled, ready-to-deploy speech dataset that you can easily access on our platform and come up with your requirements. Our data store can continuously feed data to your model throughout the process.
In the case of a custom use case, FutureBeeAI have to collect speech data with very specific features like age, gender, country, accents, etc., and for that we have the global crowd community with 10000+ data providers. Our crowd speech data collection app called Yugo that assists with scripted monologues or unscripted, spontaneous conversations. The app facilitates structured data along with metadata. At the second stage of making a custom speech dataset ready to deploy, we have to do transcription, and we offer service in that segment as well.
We have speech dataset experts who have assisted leading ASR and NLP companies. We also have crowdsourced community experts. So no matter at what stage you are in your speech model development, FutureBeeAI can assist you with all your requirements. Contact now to get started!



