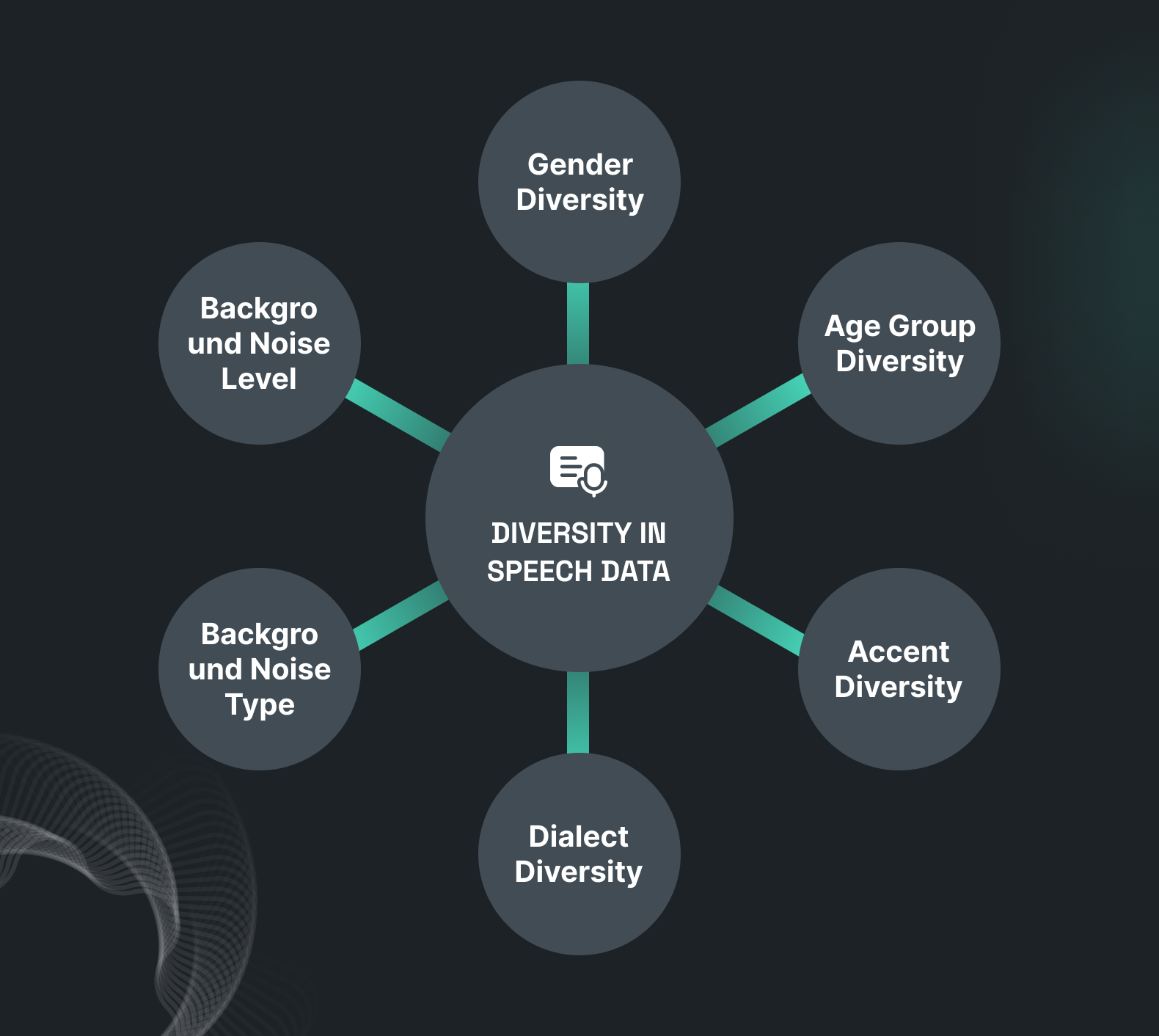
To build an accurate Automatic Speech Recognition (ASR) system for any particular language, you need high-quality and diverse speech datasets. A speech recognition dataset consists of audio recordings of the target language in all possible accents, along with a transcription file of all the speeches.
Acquiring speech datasets can be complex, as to extensively train an ASR model, you need a huge volume of audio data along with the necessary transcription. Also, this collection of audio recordings has to be diverse and unbiased. This means these audio recordings should consist of audio with all the accents, no background noise to various levels of background noise, and speech data from all possible age groups and genders. The transcription of this audio data should also be specific to the requirements. Different use cases may need different types of transcription.
 Sources to Acquire Speech Dataset
Sources to Acquire Speech Dataset
Now the first option that comes to mind while searching for any such language-specific speech dataset is an open-source speech dataset. Despite the numerous benefits of open-source datasets, such as the fact that they are most likely free, easy to access, and contributed by the community, there are a few drawbacks that make them not always the best option. There are high chances that these open-source speech datasets may not be the perfect option for your ASR use case, and so they may not serve the purpose of building a robust model.
These open-source speech datasets may not have the required quality, as there is no guarantee that they passed through an extensive quality check from native language experts. These open-source datasets may not contain enough variation in terms of speaker profile and accent, which makes them more biased. It is very rare to have a source from which one can get enough volume of a diverse speech dataset along with a quality transcription. Other than that, privacy concerns and data protection ambiguities make these datasets more vulnerable.
So for all these reasons, AI scientists often prefer to collect their own proprietary speech dataset. Collecting a custom or pre-packaged speech dataset is also not a piece of cake, as there are so many factors associated with it.
Challenges of Custom Speech Data Collection
Some of the major challenges while scaling your custom speech data collection projects are:
- Consistent technical features
- Onboarding and handling proper crowd
- Extracting user information like age, gender, accent, country, dialect, etc
- Creating guideline and make it accessible
- Record scripted monologue or conversation type of speech data
- Quality check
- Extracting structured data along with metadata
What if we say there is a platform that can solve all these issues at scale?
So with all the above mentioned reasons in mind, we have built a mobile application for speech recognition dataset collection called Yugo. We poured our years of experience working on various speech data collection projects into this application.
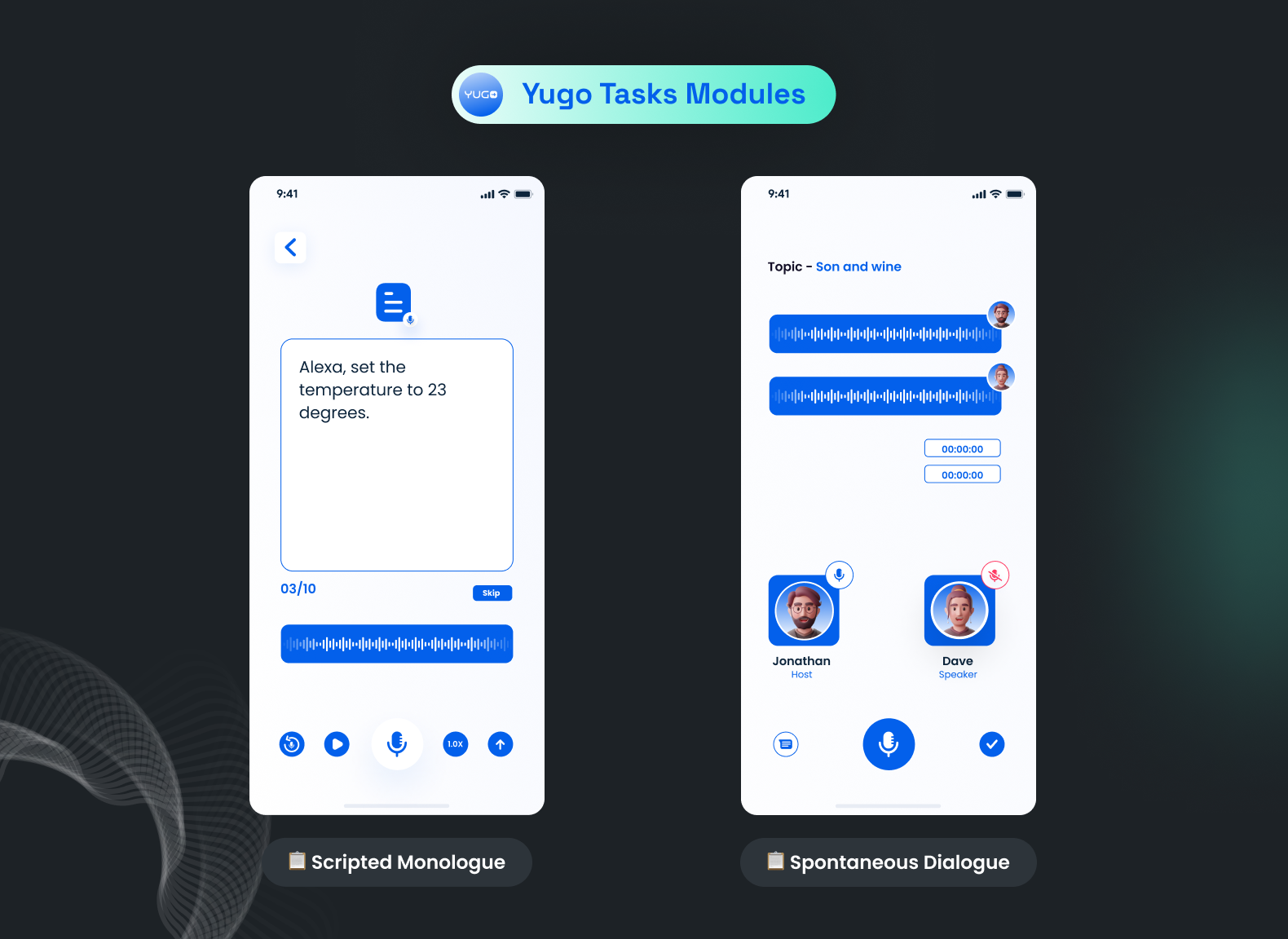
Let’s see how each of these problems is solved through the features of the Yugo application. The Yugo mobile app allows us to collect scripted prompts and human-to-human conversation-type speech data.
Features of Yugo Mobile App
Promise Consistent Technical Features
Each type of speech data needs consistent technical features like channel distribution, the format of file, bit depth, sample rate etc.
 Speech data for ASR training requires audio files in the WAV format because WAV is lossless, which means it does not lose quality when post-processing or compressing, which is not the case with MP3. Apart from this, the WAV file format also supports a higher bit depth and sample rate, which can be beneficial. Yugo provides speech data in WAV file format.
Speech data for ASR training requires audio files in the WAV format because WAV is lossless, which means it does not lose quality when post-processing or compressing, which is not the case with MP3. Apart from this, the WAV file format also supports a higher bit depth and sample rate, which can be beneficial. Yugo provides speech data in WAV file format.
The conversation type of speech data is recorded between two people on any specific topic, and at the output, we generally need separate audio files for both speakers. This means that in speaker 1's file, only speaker 1's voice will be heard, and the rest will be silent. Yugo can help with separate audio files for both speakers as well as a combined file in the case of a conversational project and a single file in the case of a scripted monologue project.
It is generally observed that scripted monologue types of speech data need bit depth of 16 bits and a sample rate of 16 kHz, and conversation recordings with separate audio files for both speakers need bit depth of 16 bits and a sample rate of 8 kHz. The Yugo app makes sure that the final speech data has these consistent technical features.
Smooth Crowd Management
Acquiring a language-specific crowd for speech data collection projects may not be easy. With a FutureBeeAI crowd of more than 10,000 community members from 50+ countries, it can be as easy as it can be. What is more difficult than finding a crowd is onboarding them for a project and managing them.
Through a well-designed admin platform, we can create specific projects, add project-specific details like language, project name, project type, and add guidelines along with audio samples. We can create login credentials for users for that particular project and share them with our crowd. People can login to our mobile app using those credentials. While logging in, we collect user metadata like age, gender, country, language, etc. This metadata can be useful in the final output.
Through admin, we can assign projects to specific people and see the status of work. Specific users can be assigned scripted monologue recordings or conversation-type projects. In a conversation-type project, the host can create the room and invite another person, and both can record the conversation. For scripted prompt recording, users can see the "sentence-to-record" on the screen that is assigned to them by the admin, and they can record it and submit it.
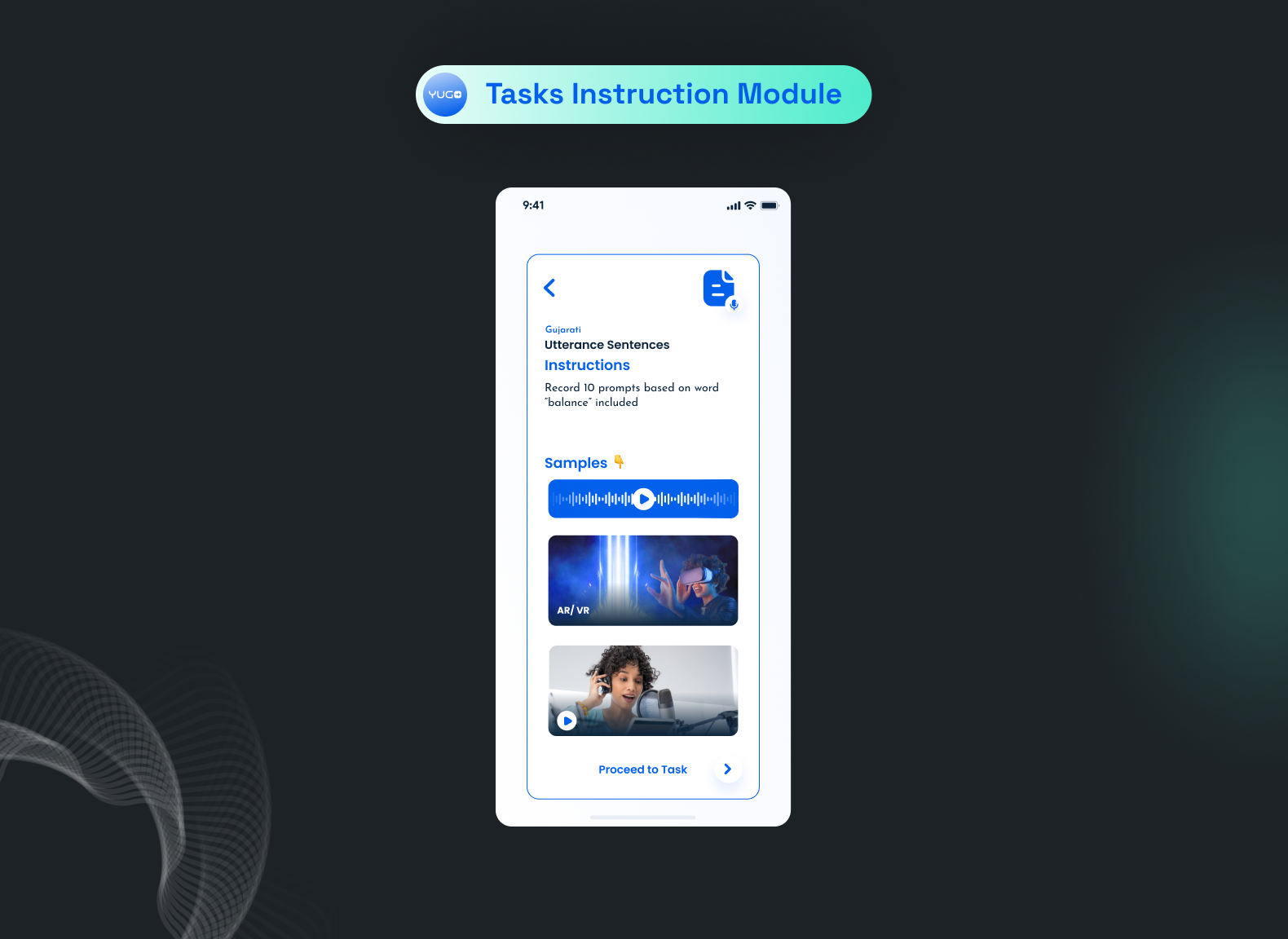
 Users can always access the guideline provided to them and check the sample audio files attached to the guideline. This can reduce the overall rejection.
Users can always access the guideline provided to them and check the sample audio files attached to the guideline. This can reduce the overall rejection.
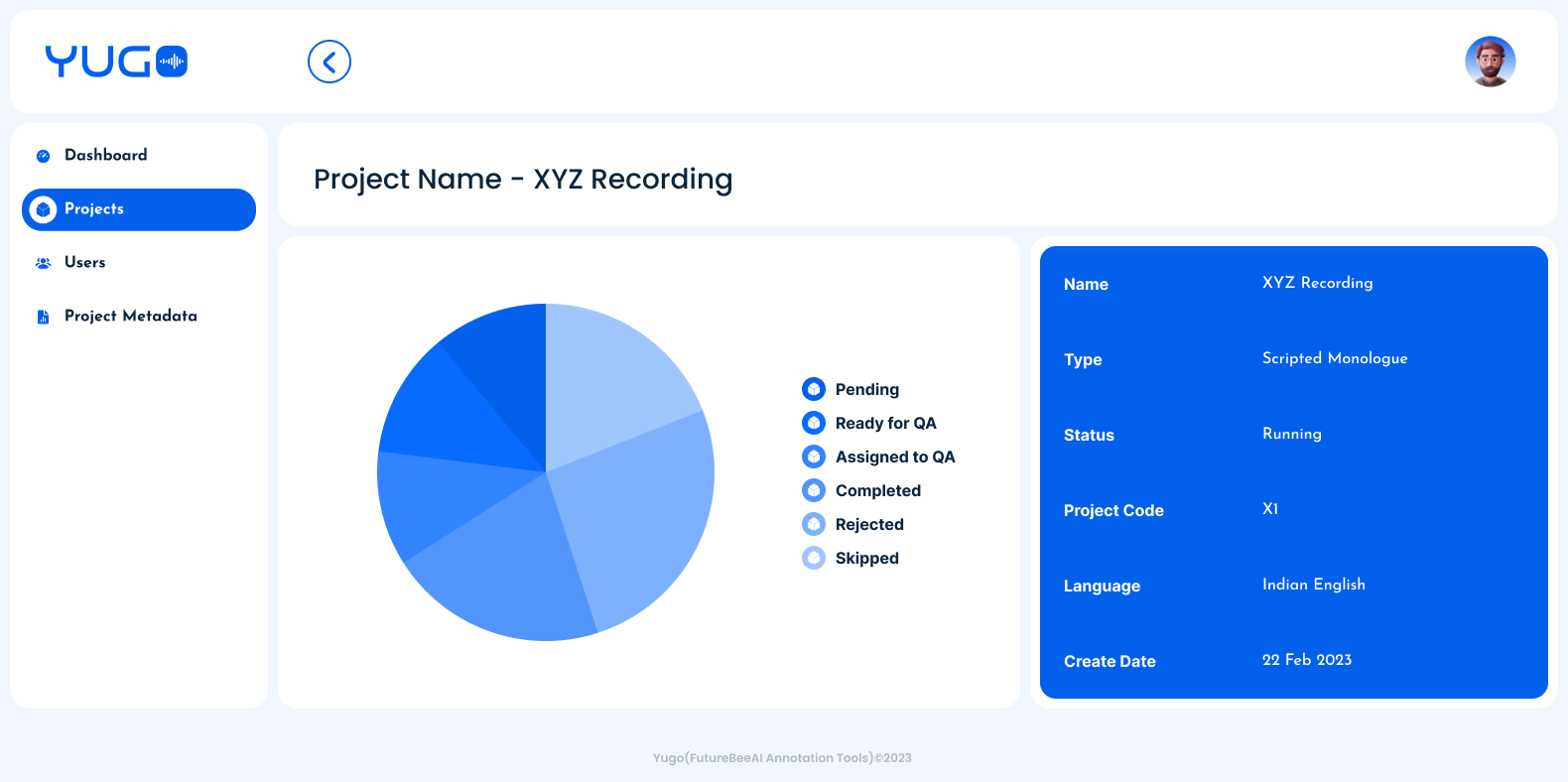
 We can always track the work status of each contributor in our admin. Once the user submits the audio file from the app, we can directly assign it for QA.
We can always track the work status of each contributor in our admin. Once the user submits the audio file from the app, we can directly assign it for QA.
 Easy Quality Check
Easy Quality Check
In our Yugo mobile app, we have a clear and easy workflow for reviewers as well. While creating projects on the admin side, we can add guidelines for reviewers as well. We can specify things to keep in mind while reviewing, along with clear criteria for acceptance and rejection, which makes the process pretty clear for the reviewer. The reviewer can access this guideline from the app anytime, which eliminates the confusion.
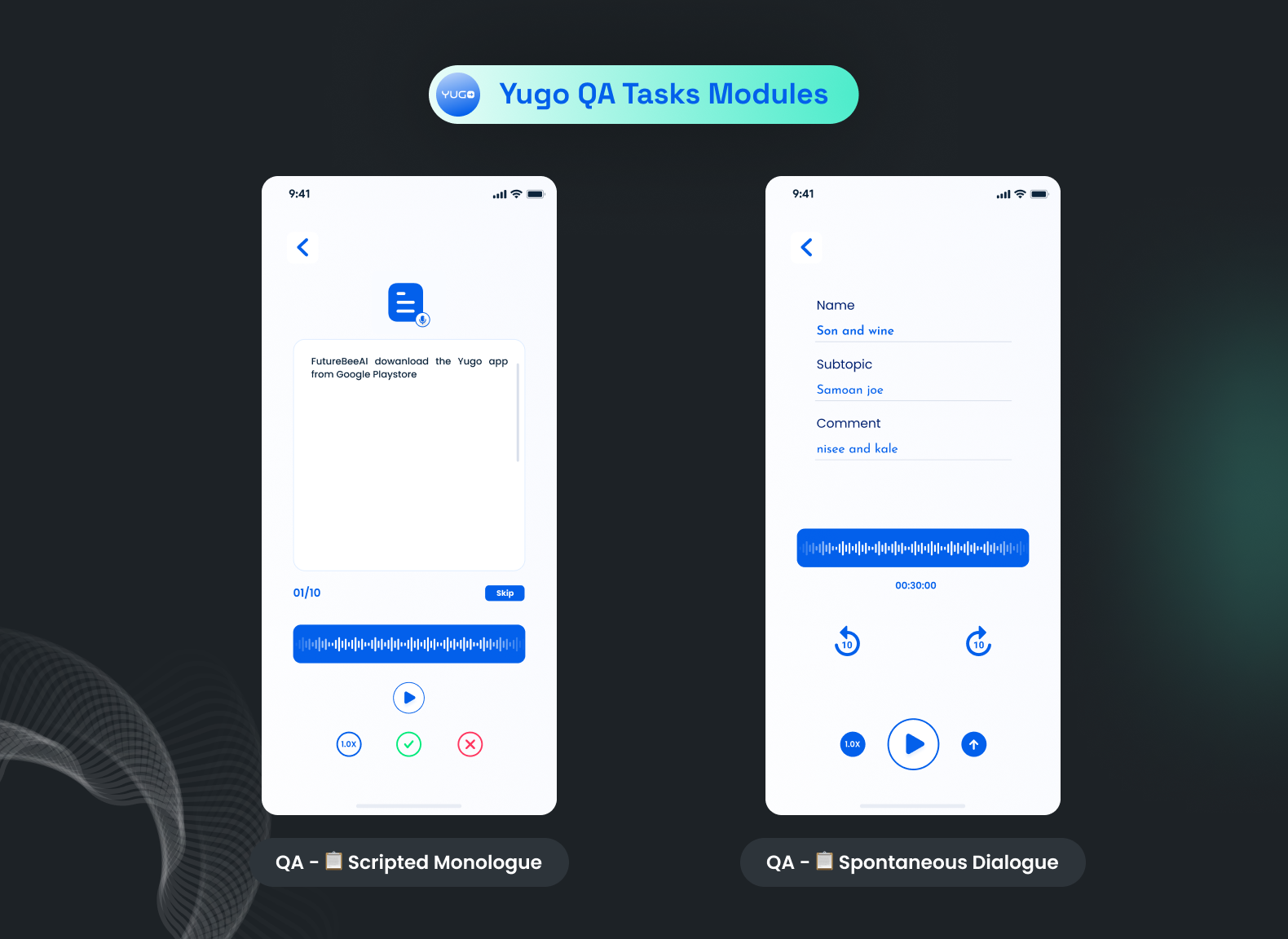 Once we assign recorded files for QA, a native language expert can listen to the file and accept or reject it based on the guidelines. QA can also cross-verify some more details, like the episode name and topic of discussion, in a conversation-type project and also add his comment to it.
Once we assign recorded files for QA, a native language expert can listen to the file and accept or reject it based on the guidelines. QA can also cross-verify some more details, like the episode name and topic of discussion, in a conversation-type project and also add his comment to it.
Once the speech data collection project is over, arranging everything in the proper format that the AI team can use takes lots of time and energy. With Yugo Admin, you can download one single Excel file for the entire project.
In that Excel file, you can access all the important metadata related to that project. You can access the audio file link, text file link, date, and user profile like name, age, gender, country, district, pincode, language, QA status, etc.
 Getting all these things in one place makes the entire process very easy and fast.
Getting all these things in one place makes the entire process very easy and fast.
How Yugo Saved Half of Time and Budget
The data team was collecting scripted monologues in German and French for one of the leading tech clients who was working on the ASR model. They needed an initial stage of data from 1,000 participants. Each individual has to record 100 scripted sentences.
They chose a process in which they gave each participant an Excel sheet with 100 different sentences. Then each participant has to read each sentence and record it using any web-based audio recorder. Once it’s recorded, the user has to download it and give it a proper rename. Similar to that renaming, the user has to create a txt file containing that sentence from the excel sheet and put both of these files in a folder.
While thinking about the process, it may not sound very complex, but while working, users have to do lots of things. Through this process, recording a single prompt of 8–10 seconds was taking almost a minute.
When we started this project, we used our speech data collection application, Yugo , for it. We collected all of the user information with the app while the user was logged in. The user can then navigate to a specific project and record the sentence, and it's done! It did not take more than 20 seconds. With such great results, we reduced the overall time to around 30-35 minutes for each user to record a batch of 100 scripted sentences, which was traditionally taking around 2 hours! Compared to the conventional method, using the Yugo mobile application resulted in a time savings of 65%.
Apart from time savings, another benefit of using the app was that we completed that project on a smaller budget. As the prior process was hectic, we have to pay users a comparatively higher amount for those redundant tasks. While using the app, we succeed in keeping the user motivated by removing redundant tasks.
Benefits of Using Collection Application Like Yugo
☑ It makes the entire process easy to manage
☑ Reduce the overall time
☑ Easy to manage and onboard crowd
☑ Clear understanding of the progress of the project
☑ Easy to access the guideline
☑ Flawless recording and QA stages
☑ Easy gathering of structured data
☑ Consistent technical features
Takeaway
People, processes, and tools all play a role in the success of any data collection project. It is very obvious that collecting training datasets is an expertise-driven task, and getting assistance from someone like FutureBeeAI can help you collect an unbiased and quality training dataset.
Apart from that, having state-of-the-art tools (SOTA) can be one of the criteria for choosing a data provider company. The dual-speaker conversation type of feature is not available in any speech data collection app as of now, and our in-house team of excellent developers helps us get the edge over competitors.
So no matter what your use case is or what type of speech data you need, you can get in touch with our data experts, and they will assist you with almost everything!







