


Have you remembered what’s the first thing you’ve seen with your naked eyes?
Well, none of us would have remembered it because at the time we were in the womb of our mother and also because we are not capable of developing consciousness in the first 2 to 3 years.
The point we’re trying to make is that in machine learning, the understanding of image recognition has been influenced by the concept of human vision. Not just image recognition but all other subfields of computer vision. The way that the human visual system processes information has been used as a model for developing image recognition algorithms. For example, researchers have studied the way that the human brain processes visual information to identify objects and patterns and have used this information to develop algorithms that can recognize objects in images.
Additionally, understanding human vision has led to a deeper understanding of the limitations of current image recognition systems. For example, it is very common for human vision, within a span of seconds, to recognize objects under a wide range of conditions, including different lighting, orientations, and scales. However, current image recognition systems often struggle with these variations and require much computational processing power to attain just to recognize one image correctly. If consider market predictions then with 17.6% CAGR, the image recognition market worth USD 86.32 billion by 2027 says GlobeNewswire.com
So, let’s just dive straight into the algorithmic-driven image recognition systems.
What is Image Recognition?
Image recognition is the process of using computer algorithms to identify and classify objects, people, scenes, and other elements within images. In the context of machine learning, image recognition is achieved by training artificial intelligence (AI) models using large amounts of labeled image data.
There are various machine learning techniques used to create AI models for image recognition, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and support vector machines (SVMs). These models learn to recognize patterns and features in the image data through repeated exposure to labeled examples during the training process.
Subsets of Image Recognition

Object Detection
Object detection is a key technology behind advanced driver assistance systems (ADAS) that prevents traffic accidents. It is also used in many other applications, such as video surveillance and image retrieval systems.
The main goal of object detection is to locate the position of an object in an image or video and classify it into a predefined class. The process of object detection typically starts with the creation of a set of candidate bounding boxes around regions of interest in an image or video frame. These bounding boxes are then fed into an object classifier that assigns a class label to each bounding box.
Image Classification
It is where an algorithm is trained to identify and categorize objects or scenes in digital images into pre-defined classes. This can be achieved through various techniques such as feature extraction, dimensionality reduction, and machine learning algorithms.
The first step in image classification is to extract features from the image that are relevant to the task at hand. These features can be things like color, texture, shape, or edge information.
Image Segmentation
Image segmentation is the process of dividing an image into multiple segments or regions, each of which corresponds to a different object or part of the image. The goal of image segmentation is to partition an image into semantically meaningful regions that correspond to objects or parts of objects in the image.
The performance of an image segmentation algorithm is typically evaluated based on accuracy, completeness, and consistency. Accuracy refers to the ability of the algorithm to correctly segment the objects in the image; completeness refers to the extent to which the objects are completely segmented; and consistency refers to the stability of the segmentation results over time.
How does Image Recognition work?
Image recognition has evolved greatly over time, from early attempts to identify and categorize images using simple techniques like edge detection and pattern recognition to the current state-of-the-art deep learning methods that can recognize and categorize images with remarkable accuracy.
There are several approaches to perform image recognition.
Conventional Algorithms
Template matching: This basically takes place by comparing a target image to a set of predefined templates and finding the closest match.
Feature-based recognition: This method involves detecting and extracting features from an image, such as corners, edges, or blob-like structures, and then using these features to recognize objects.
Scale-Invariant Feature Transform (SIFT): This is a feature-based recognition technique that is invariant to scale, orientation, and affine transformations.
Speeded-Up Robust Features (SURF): A feature-based recognition technique that is faster than SIFT and is suitable for real-time applications.
Bag of Visual Words (BoVW): This is a feature-based recognition technique that represents an image as a histogram of visual words, which are quantized features obtained from a dictionary of visual words.
Histograms of Oriented Gradient (HOG): This is a feature-based recognition technique that represents an image as a histogram of gradient orientations, which is useful for detecting objects based on their shape.
The Viola-Jones algorithm: It is fast and efficient, and it can detect faces in real time with good accuracy, making it a popular choice for face detection in a variety of applications. However, it has some limitations, such as a sensitivity to illumination changes, occlusions, and viewpoint changes, and it may not perform well on faces with non-frontal poses. Nevertheless, it remains one of the most widely used algorithms for face detection and continues to be an important contribution to the field of computer vision.
Machine Learning Algorithms
K-Nearest Neighbors (KNN): A simple, non-parametric method for image recognition that classifies an image based on its similarity to a set of labeled images.
Support Vector Machines (SVMs):A supervised learning method that can be used for image recognition by mapping the images into a high-dimensional feature space and finding a hyperplane that separates the classes.
Convolutional Neural Networks (CNNs):This is the most common approach to deep learning, where CNNs use a series of convolutional layers to extract features from the image and a series of fully connected layers to make the final classification.
Recurrent Neural Networks (RNNs): This is also a deep learning model that can be used for image recognition by processing the image data in a sequential manner and making predictions based on the entire sequence of image features.
Data Sourcing/Gathering/Collection
The process typically starts by exposing the machine to many examples, or training datasets of the image it needs to recognize. This training data is used to train the AI how to identify the features and patterns of the image.
Data collection requires relevant sources from which you can find the model’s object-driven data in significant quantity and quality. Our data pool consists of 2000+ pertained datasets ready to launch your next face recognition or object detection model.
For accurate and faster performance, data must be collected with variations like view-point, deformation, occlusion, and inter-class keeping on paper.
Data Annotation and Preprocessing
Data preparation covers the part of annotating gathered image datasets and setting up images by breaking them down into smaller components (generally pixels, in which each pixel has its own numerical value) and examining each one individually.
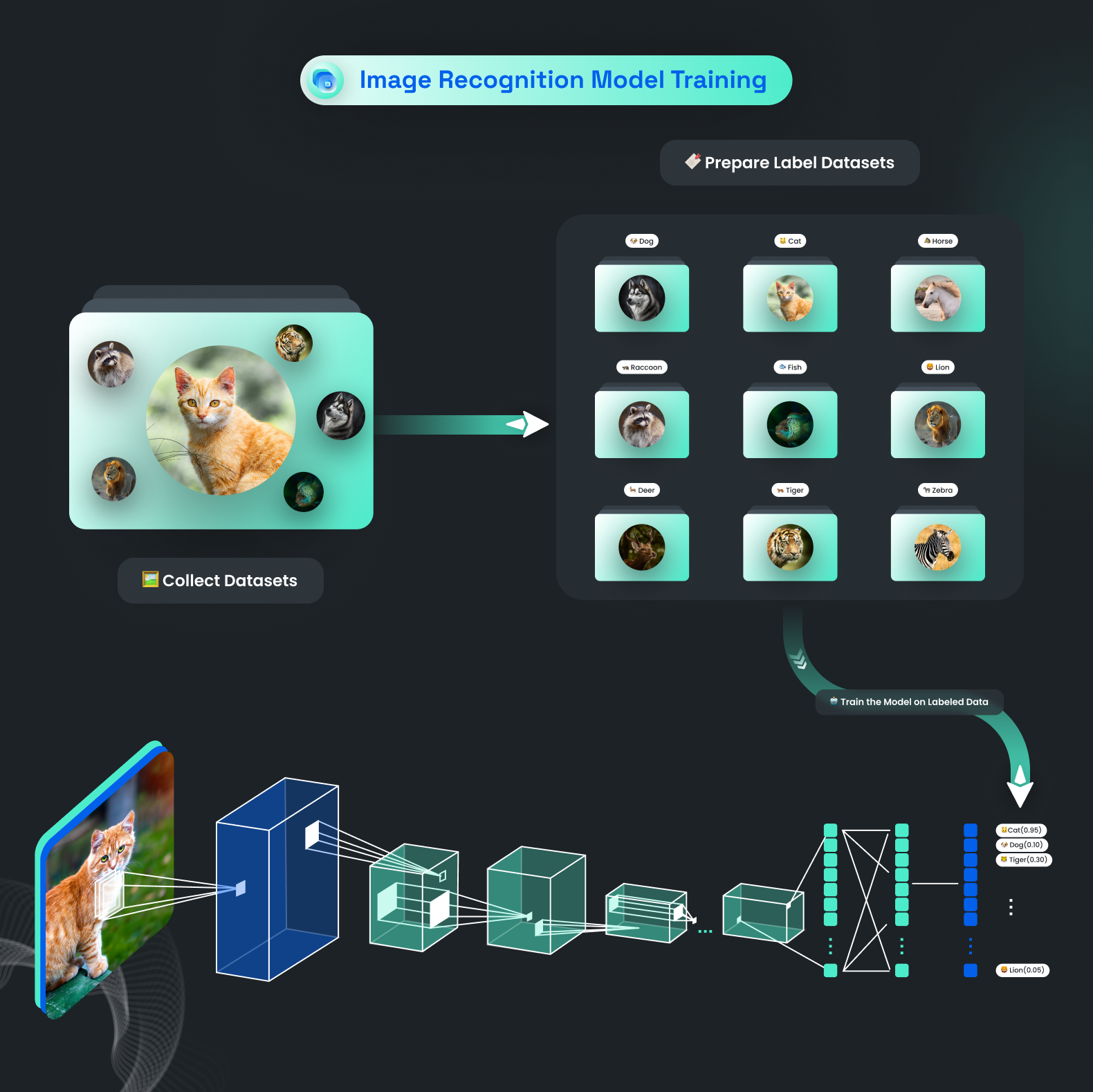
Let’s Understand Different Layers of CNN Architecture
In CNN architecture, there are 4 layers: the convolution, the ReLUs, the pooling, and the fully connected layers.
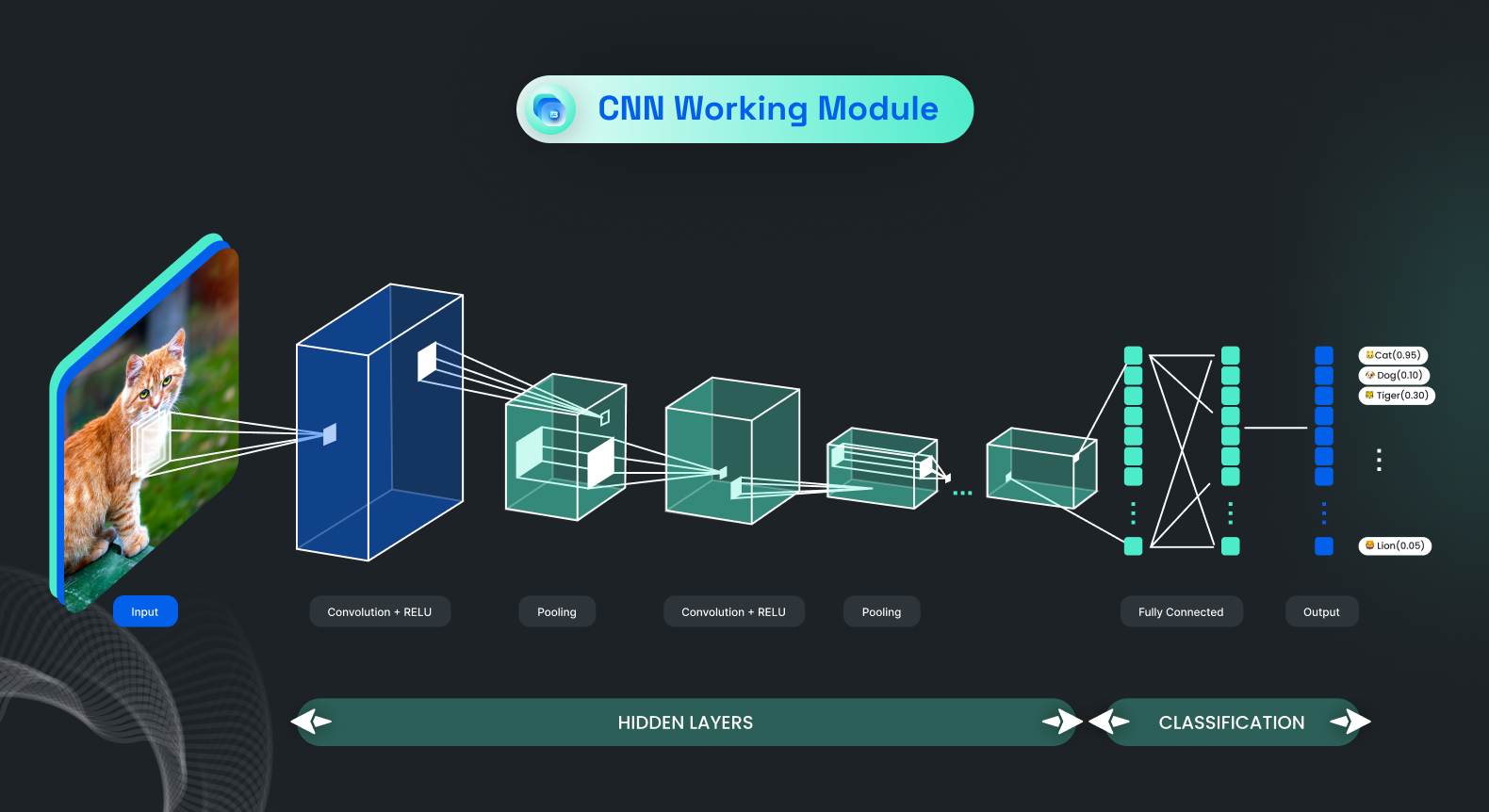
The Convolution Layer
In simple terms, a Convolutional Neural Network (CNN) breaks an image into small pieces called features to understand its shapes and patterns. These features scan the image to see how well they match. If the match is good, the score in that area is high. If the match is poor, the score is low or zero.
The process of getting the scores is called filtering, and each feature creates a filtered image with high and low scores. This process of scanning the image for each feature is called convolution. The filtered images are then combined to create the convolution layer.
ReLU Layer
The ReLU (Rectified Linear Unit) layer is a commonly used activation function in Convolutional Neural Networks (CNNs). It is used to introduce non-linearity into the network, which allows the model to learn complex relationships between the inputs and outputs.
The ReLU activation function takes the input value x and returns the maximum of 0 and x, or simply x if x is positive and 0 if x is negative. This means that negative values are replaced with 0, while positive values are unchanged. The ReLU activation function can be written mathematically as:
f(x) = max(0, x)
The ReLU layer is typically added after each convolutional layer, and before any fully connected layers. This is because the convolutional layer produces a feature map that is linear in nature, and the ReLU layer is used to introduce non-linearity into the feature map so that the model can learn more complex relationships between the inputs and outputs.
The ReLU activation function is computationally efficient and has been shown to work well in practice. Additionally, it is relatively easy to optimize, since it is a piecewise linear function that is either 0 or x, with no gradient to calculate when x is negative.
Pooling Layer
The pooling layer is a common component of Convolutional Neural Networks (CNNs) that is used to reduce the spatial dimensionality of the feature map produced by the convolutional layer. This is done to reduce the number of learnable parameters in the model and prevent overfitting.
The pooling layer works by dividing the feature map into a set of non-overlapping regions and computing a summary statistic for each region. The most common summary statistic is the maximum value, but other statistics such as average or sum can also be used. The result is a reduced-size feature map that retains the most essential information from the original feature map.
There are two types of pooling layers commonly used in CNNs: max pooling and average pooling. Max pooling takes the maximum value from each region, while average pooling takes the average. Max pooling is more commonly used because it has been shown to work well in practice and provides a more robust representation of the data.
The pooling layer has a pooling kernel size and a stride, which determine the size of the regions in the feature map and how far apart they are. The pooling kernel size and stride are hyperparameters that can be tuned to control the size of the output feature map and the amount of spatial information that is preserved.
Fully Connected layer
A fully connected layer, also known as a dense layer, is a component of a Convolutional Neural Network (CNN) that connects all of the neurons in one layer to all of the neurons in the next layer. This type of layer is called "fully connected" because each neuron in the layer receives input from all neurons in the previous layer(hidden layers).
The fully connected layer is typically used as the final layer in a CNN, after the convolutional and pooling layers have processed the input image to extract relevant features. The fully connected layer receives the feature map as input, and applies a set of weights to the features to produce a prediction.
In a fully connected layer, each neuron computes a weighted sum of its inputs and applies an activation function to produce its output. The activation function can be a ReLU, sigmoid, or other activation function, depending on the problem being solved and the design of the network.
The weights in a fully connected layer are learned by the network during the training process. The network updates the weights in response to the error in the prediction, gradually improving the accuracy of the model.
Popular Model Architectures for Image Recognition
You Only Look Once (YOLO)
YOLO (You Only Look Once) is a popular real-time object detection system that is able to detect objects in an image or video frame with high accuracy. It was developed by Joseph Redmon et al. in 2015 and has since become one of the most widely used algorithms in computer vision.
It works by dividing the image into a grid of cells, and each cell predicts the presence of multiple bounding boxes and their corresponding class probabilities. Unlike other object detection algorithms that use two-stage methods, YOLO processes the entire image in one forward pass through a neural network, making it faster and more efficient.
YOLO has two key features that make it particularly effective: it uses anchor boxes to handle multiple object scales and aspect ratios, and it applies Non-Maximal Suppression (NMS) to remove overlapping bounding boxes and reduce false positive detections.
YOLO is used in a wide range of applications, including self-driving cars, security systems, and video surveillance. Its real-time performance, accuracy, and versatility make it a popular choice for many computer vision tasks.
In recent times the 8th version of YOLO has been released by Ultralytics. The YOLOv8 model is a highly advanced and innovative solution that builds upon the achievements of previous YOLO versions. It incorporates new features and enhancements to enhance performance and versatility, making it a state-of-the-art (SOTA) solution in the field.
Single Shot Detector (SSD)
The SSD algorithm uses a single deep neural network to make predictions on the input image, hence the name "Single Shot." The network consists of multiple convolutional and fully connected layers, with the final layer producing predictions for the location and class of objects in the image.
The SSD algorithm uses a technique called anchor boxes to handle the variations in object scales and aspect ratios. Anchor boxes are pre-defined bounding boxes of different shapes and sizes that are placed at different locations in the image. The network then predicts the class and location of objects relative to these anchor boxes.
The SSD algorithm also uses non-maximum suppression to remove overlapping detections and improve the accuracy of the predictions. The output of the network is a set of bounding boxes and class scores, which can be used to visualize and interpret the object detections in the image.
Applications of Image Recognition
AR/VR/MR
AR Smart Glasses
AR smart glasses use image recognition to display information and digital content on top of the real-world environment. Image recognition algorithms can be used to identify objects and surfaces in the environment, allowing the AR content to be anchored to specific locations and objects.

VR/AR Head-Mounted Displays (HMDs)
To track the user's head and eye movements, allowing the user to interact with the virtual or augmented environment in a more natural and intuitive way.
.webp)
Marker-Based AR
Marker-based AR uses image recognition algorithms to detect and track specific visual markers in the environment, allowing AR content to be displayed in response to the location of the markers. This is a popular approach for AR educational and entertainment applications.

Spatial Mapping
Image recognition algorithms can be used to build 3D spatial maps of the environment, allowing VR and AR content to be placed and interacted with in the virtual or augmented space. This is a critical technology for immersive VR and AR experiences.

Transportation
Autonomous Vehicles
Image recognition is a critical technology for autonomous vehicles, allowing the vehicle to perceive and understand its surroundings. Image recognition algorithms can be used to detect and identify road signs, traffic lights, other vehicles, pedestrians, and other objects in the environment.

Traffic Management
To analyze traffic patterns and monitor traffic flow, allowing traffic management systems to optimize traffic routing and reduce congestion.

License Plate Recognition
Identify and recognize license plates on vehicles, allowing for automated toll collection, parking management, and vehicle tracking.
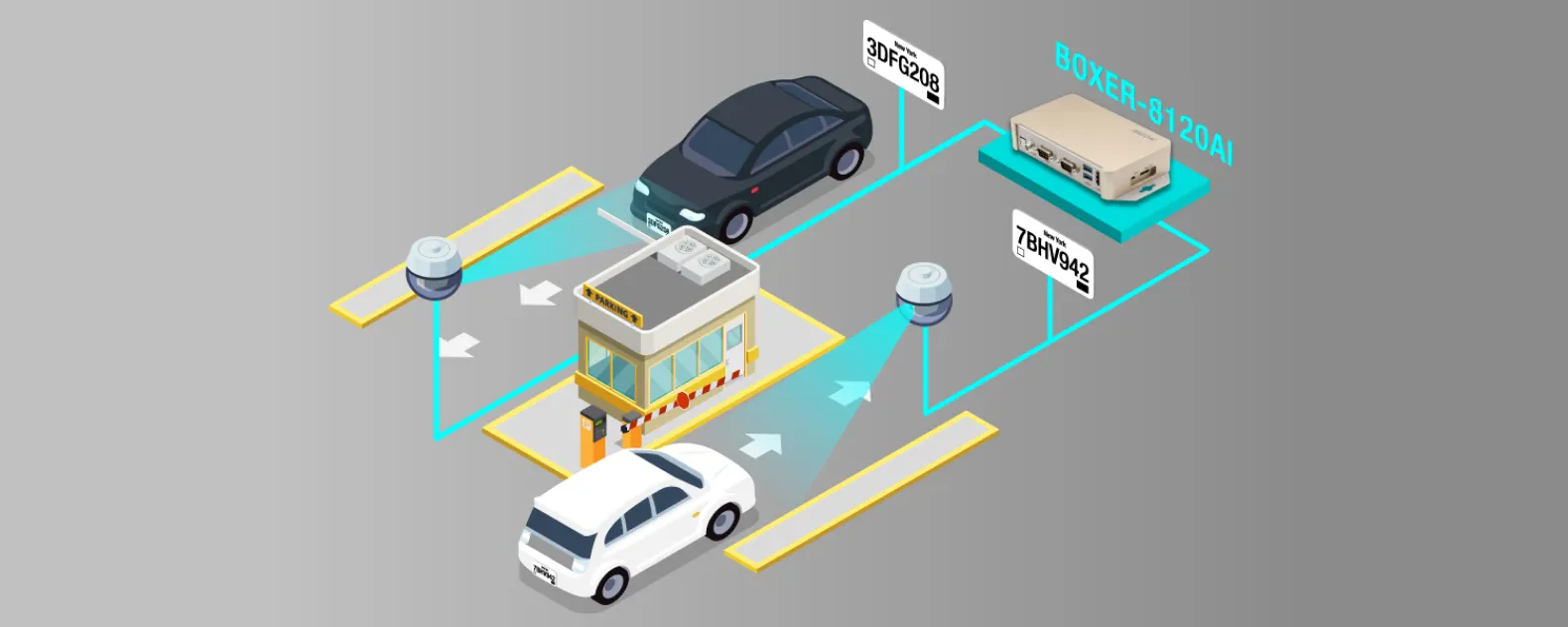
Vehicle Safety Systems
Image recognition algorithms can be used to detect potential safety hazards in the environment, such as pedestrians, bicycles, or other vehicles. These systems can alert the driver or trigger automated safety responses to prevent accidents.
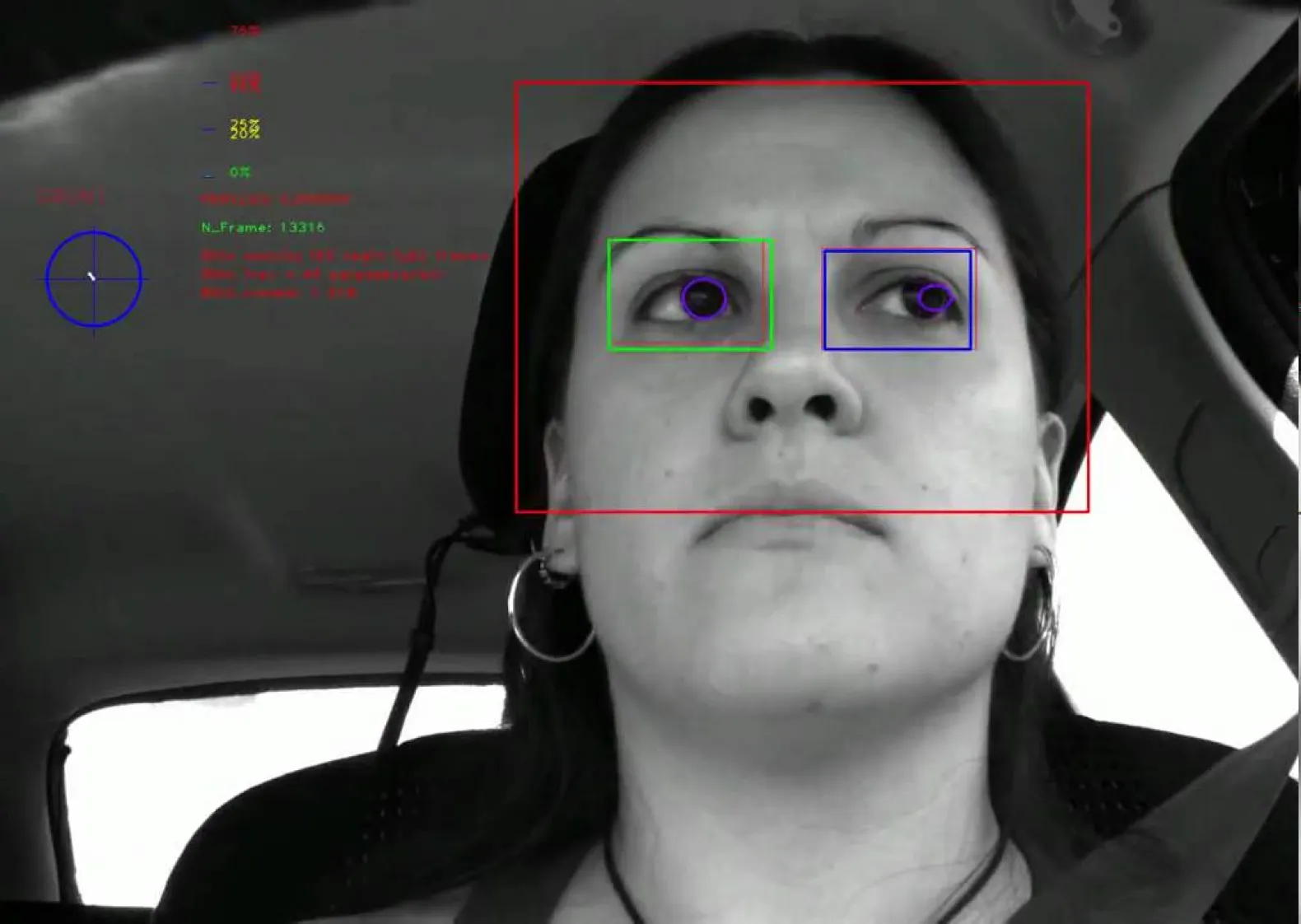
Public Transport
Track and manage public transport vehicles, such as buses and trains. This allows for real-time tracking of vehicles and improved management of transport schedules and routes.

Parking Management
Detect and manage parking spaces, allowing for real-time availability information and optimized parking management.

Healthcare
Image recognition plays a crucial role in the healthcare industry, enabling advancements in areas such as disease diagnosis, medical imaging analysis, and patient monitoring.
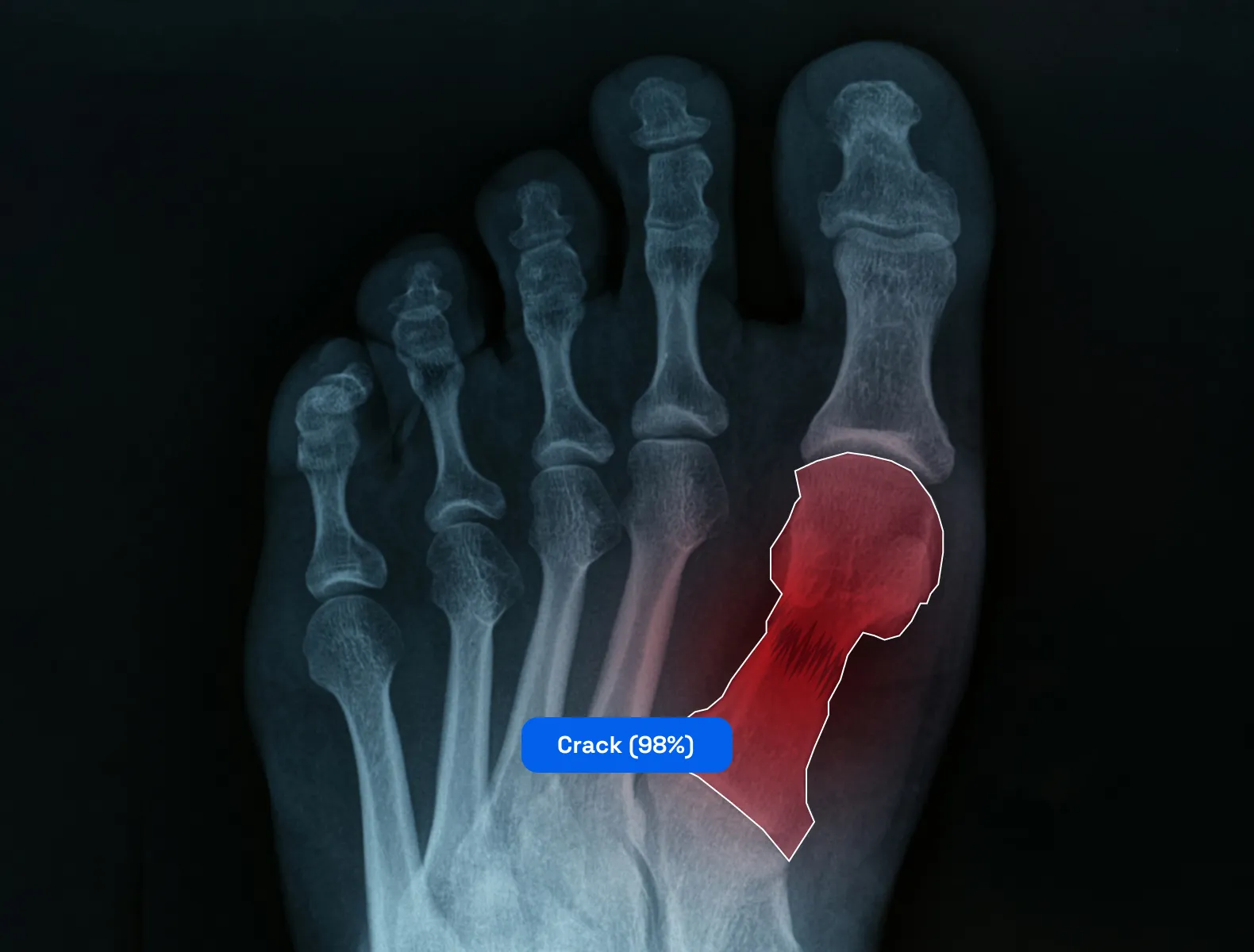
Image recognition algorithms can be used to analyze medical images, such as X-rays, MRI scans, and CT scans, to detect and diagnose diseases, monitor patient progress, and provide information for treatment planning.
In addition, image recognition can be used for patient monitoring, such as monitoring vital signs, detecting falls, and tracking movement patterns to detect changes that may indicate a decline in health.
Retail, E-commerce, and Social Media
Applications of Image Recognition in Retail include product search and identification, augmented reality try-on, and in-store navigation. In e-commerce, it is used for product search and recommendation, visual search, and fraud detection. In social media, it is utilized for tagging friends and objects in photos, creating filters, and detecting inappropriate content.

Safety and Surveillance
Image recognition has numerous applications in the field of safety and surveillance, including face recognition for access control, license plate recognition for traffic management, object detection for security surveillance, monitoring public spaces for suspicious activity, identifying individuals in a crowd, tracking the movements of individuals in real-time, and enhancing video surveillance with automatic alerts.

Logistics and Manufacturing
Image recognition has various applications in logistics and manufacturing, including automated item sorting and routing, quality control and inspection, tracking and tracing of products, warehouse management and inventory control, and inspection of products for defects and anomalies. It is also used for identifying and tracking vehicles, containers, and cargo, as well as monitoring production lines and machines for efficiency and maintenance purposes.

Wrapping Up
Image recognition is the first step towards making machine or computer vision more like human vision. Image recognition algorithms as the field is a vast subject and will enhance as the advancements are brought by great minds working behind these technologies.
According to dimensional Analysis research, up to 96 percent of organizations have issues with training data, both in terms of quality and quantity. These organizations are unable to acquire datasets with the required quality parameters and in enough quantity to train the model accurately. That means choosing the right data enabler can get you half a win.
Obsessed with helping AI developers over 5 years in the industry, we here at FutureBeeAI thrive on world-class practices to deliver solutions in every stage of AI dataset requirements, from selecting the right type of data and structuring unstructured data to stage-wise custom data collection and pre-labeled off-the-shelf datasets.
Browse more resources for computer vision and data annotation domain.
🔗 Data Annotation and Labeling Techniques for Machine Learning: A
Beginner’s Guide
🔗 Important Factors to Consider When Choosing a Data Annotation
Outsourcing Service
🔗 Data Annotation Techniques for Computer Vision: A Look at the Most Common
Types
🔗 What is Driver Drowsiness Detection System & How does training
data aid DDS algorithms?
🔗 Answering the what, why & how's of ADAS & the role of
datasets in training the ADAS algorithms
🔗 Polygon Annotation: Methods, Reasons, and Use Cases



