Language models are a fundamental component of modern natural language processing (NLP) systems. They are essentially algorithms that analyze and understand human language. The importance of language models in our daily lives can be seen in the increasing popularity of the recently launched ChatGPT, a large language model (LLM) by OpenAI that has received a great response from all over the world and become the fastest platform to get 5 million users.
People are using language models for a number of different language-based tasks, for instance:
question-answer, summarization, translation, text completion, blog writing, etc.
Language models have made significant advancements in the past few years and are now widely used in various industries. In this blog, we will dive deep into language models, and discuss what is a language model, different types of languages model, and their use cases.
What is a language model?
A language model is a probability distribution over sequences of words. It is used in natural language processing to predict the probability of a sequence of words in a language. Language models are trained on text corpora (sets of sentences) in one or many languages and learn the probabilities of different word combinations that appear in the training dataset. Once trained, the language model can be used to generate new text by predicting the probability of the next word in a sentence. In short, an AI model which can understand and generate new text is called a language model.
A language model's main goal is to capture statistical patterns and dependencies in language. For example, a language model trained on a large corpus of English text would learn that the phrase "I am" is often followed by a verb, such as "going" or "eating". The language model can generate new text that is grammatically correct and semantically meaningful by understanding these patterns.
But not all language models are created equal, some are trained for general purposes and some are fine-tuned for specific tasks.
Types of Language Models
Language model development is not new but it has gained popularity in the past few years and now we have some great language models including BLOOM, Claude, Bard, etc. The techniques used for developing language models are mainly classified as
- N-Gram Models
- Neural Network-Based Model
N-Gram based Language Models
An n-gram is a sequence n-gram of n words: a 2-gram (which we’ll call bigram) is a two-word sequence of words like “move please ”, “turn on”, or ”your homework”, and a 3-gram (a trigram) is a three-word sequence of words like “turn on light”, or “I love you”. The N-gram method is a statistical language modeling technique used in natural language processing (NLP). It involves analyzing text data and counting the frequency of sequences of N words (or tokens) that appear in a corpus of text. These sequences are referred to as N-grams, where "N" refers to the number of words in the sequence.
In the N-gram method, we are using the Markov assumption that the probability of a word depends only on the previous word. Markov models are the class of probabilistic models that assume we can predict the probability of some future unit without looking too far into the past.
For example, a 2-gram model (also known as a bigram model) would count the frequency of every two-word sequence in the text corpus. So, if the sentence "The man sat on the chair" appeared in the corpus, the 2-gram model would count the frequency of "the man", "man sat", "sat on", "on the", and "the chair".
Once the N-grams have been counted, the model can be used to predict the probability of the next word in a sequence. For example, given the sequence "The man sat", the model can predict the probability of the next word being "on", "near", "in", or any other word that has appeared after "The man sat" in the text corpus.
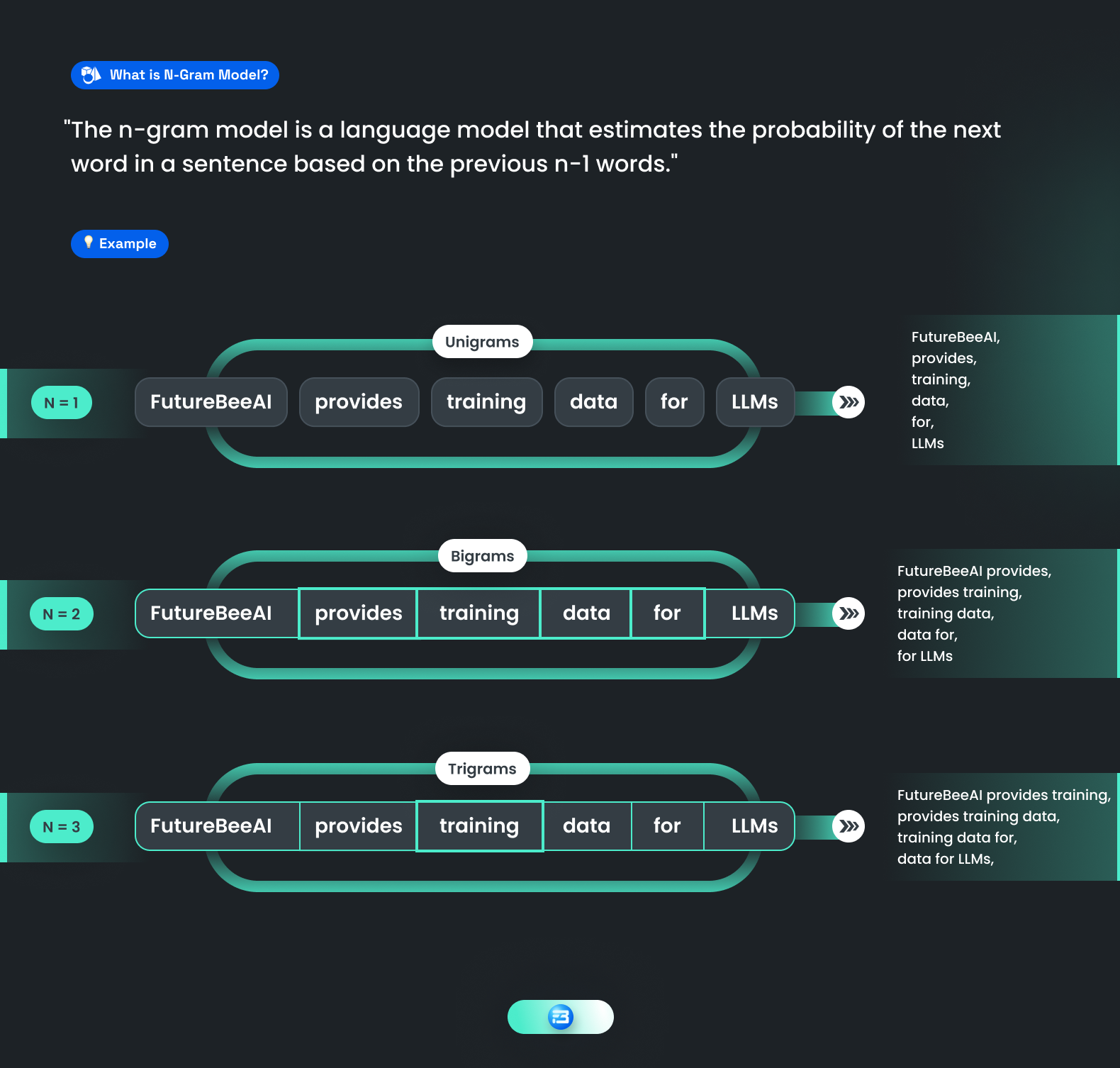 The N-gram method is a simple and efficient way to build a language model, but it has some limitations. One of the main limitations is that it can only capture local dependencies between adjacent words, so it may not be able to capture long-range dependencies or complex linguistic structures. Additionally, the method can suffer from data sparsity when the corpus is small or when the N-gram size is large.
The N-gram method is a simple and efficient way to build a language model, but it has some limitations. One of the main limitations is that it can only capture local dependencies between adjacent words, so it may not be able to capture long-range dependencies or complex linguistic structures. Additionally, the method can suffer from data sparsity when the corpus is small or when the N-gram size is large.
Data Sparsity means n-gram will give zero probability to some combinations of words which are not available in training data, even though they may be acceptable English combinations.
Neural Network based Language Model
Neural network-based language models use neural networks to predict the probability of the next word in a sequence of text. These models have become increasingly popular in recent years due to their ability to capture long-range dependencies and more complex linguistic structures than N-gram models. Neural network-based language models ease the data sparsity problem by the way they encode inputs.
The basic architecture of a neural network-based language model typically involves an input layer that receives a sequence of words or tokens, followed by one or more hidden layers that perform a nonlinear transformation of the input. The output layer predicts the probability distribution of the next word in the sequence based on the hidden layer's representation of the input.
One of the neural network architectures for language modeling is the recurrent neural network (RNN). RNNs are well-suited for modeling sequential data, such as text because they can maintain a "memory" of previous inputs and use that information to predict future inputs.
However, the main drawback of RNN-based architectures stems from their sequential nature. As a consequence, training times soar for long sequences because there is no possibility for parallelization. The solution to this problem is transformer architecture.
The most popular architecture for neural network-based language modeling is the transformer model. Transformers are based on a self-attention mechanism that allows the model to attend to different parts of the input sequence to make predictions. The transformer model has been shown to achieve state-of-the-art performance on a variety of natural language processing tasks, including language modeling. The GPT models from OpenAI and Google’s BERT utilize the transformer architecture.
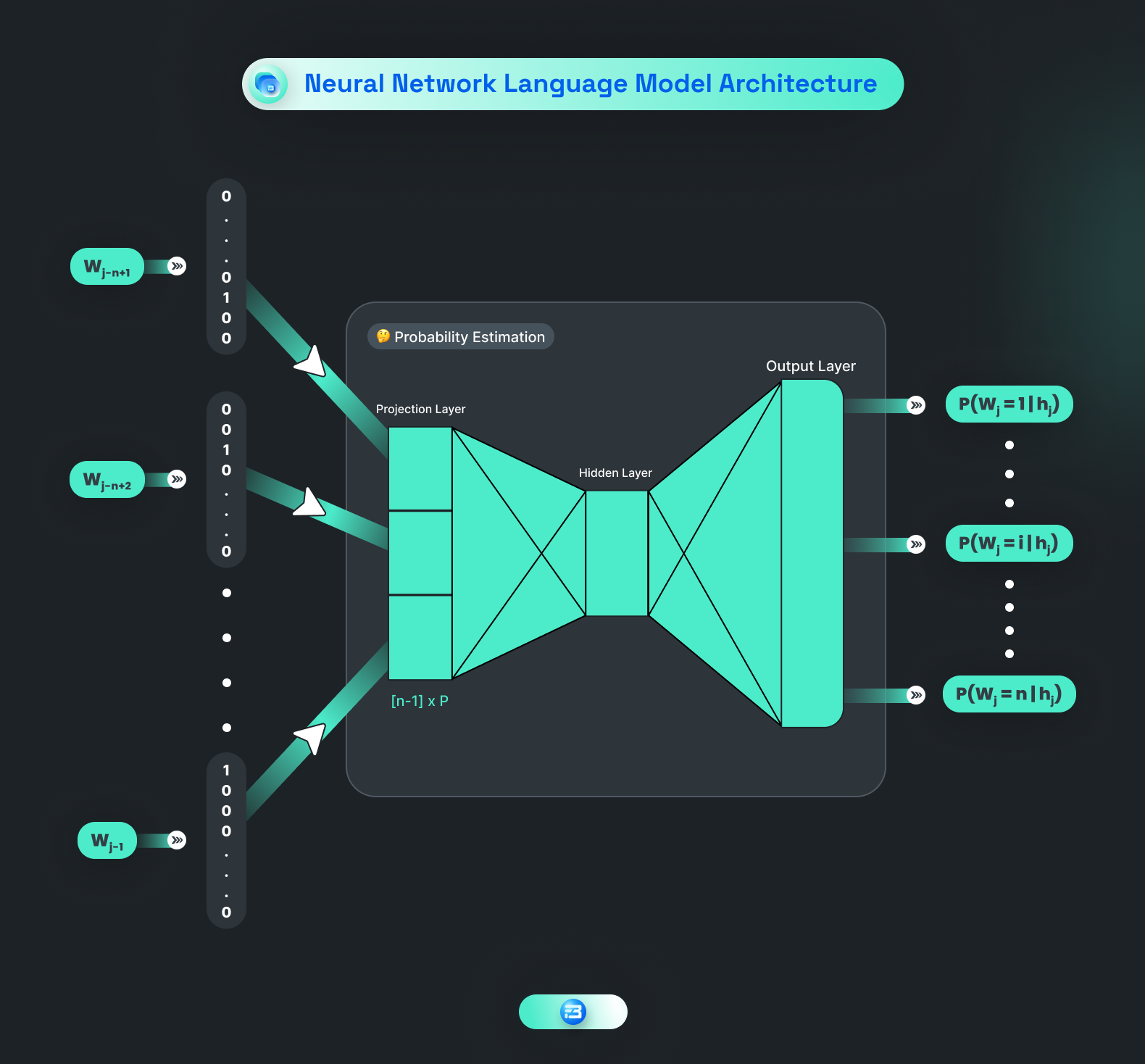 Neural network-based language models have several advantages over N-gram models, including their ability to capture long-range dependencies and more complex linguistic structures. However, they also require a larger amount of training data and computational resources to train compared to N-gram models.
Neural network-based language models have several advantages over N-gram models, including their ability to capture long-range dependencies and more complex linguistic structures. However, they also require a larger amount of training data and computational resources to train compared to N-gram models.
Large, Specific, and Edge Language Models
There are different types of language models based on their level of generalization, specificity, and computational requirements.
Large Language Model
Large language models are typically trained on massive amounts of text data, such as the entire internet or large collections of books, articles, and other written material. They use sophisticated algorithms and neural networks to learn the patterns and structure of language, enabling them to generate coherent and meaningful responses to a wide variety of prompts and queries.
These models are also known as Generative AI models, because they can generate text in a variety of ways, including by predicting the next word in a sentence, completing a sentence or paragraph, or generating a new text from scratch based on a given topic or prompt. Examples of large language models include GPT-4, GPT-3.5, BERT, RoBERTa, Claude, BLOOM, etc.
Although Large language models are a very powerful tool for generating content, we should cross-check the content generated by these models because they can generate wrong information as they are trained on the data from the web that may have wrong pieces of information. These models can be used for general purposes like blog writing, and can also be used as foundation models for developing specific use case language models.
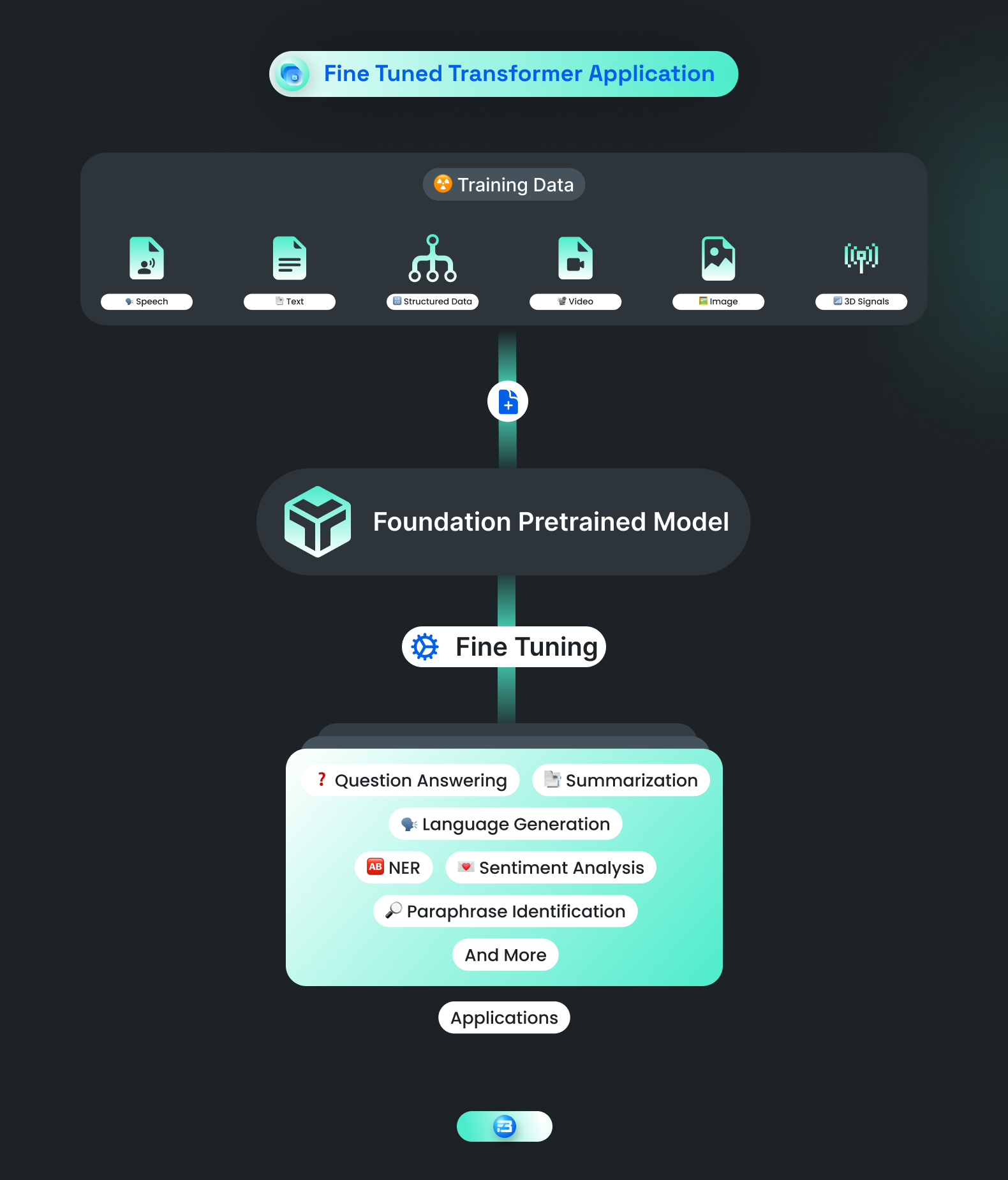
Specific or Fine-tuned Language Model
A specific or fine-tuned language model is a pre-trained foundation model that has been further trained for a specific domain or task. Fine-tuning involves using a smaller training dataset of domain-specific text to fine-tune the pre-trained foundation model to achieve better performance on the specific use case. It allows the model to learn the domain-specific nuances and vocabulary, making it more accurate and efficient.
As these models are fine-tuned with specific training data, there is very less chance that they can generate wrong information. Generally for fine-tuning the training data is created with the help of experienced persons and for that, a language model developer can take help from training service providers. For training these models many different training datasets can be created like closed question-answer datasets, open-ended question-answer datasets, chain of thoughts datasets, etc.
Examples of fine-tuned language models include models that are specifically trained for sentiment analysis, machine translation, summarization, named entity recognition, etc.
 Edge or On-Device Language Model
Edge or On-Device Language Model
Edge models, are intentionally small in size. An edge or on-device language model is a type of language model that is designed to run on a local device, such as a smartphone, rather than relying on cloud computing. Edge models are lightweight and optimized for lower computational resources and limited memory, making them suitable for deployment on low-power devices. These models are often used in applications where low latency and offline processing are critical, such as speech recognition or natural language processing in mobile apps. Examples of edge language models include Google translate, Google's TensorFlow Lite, and PyTorch Mobile.
Importance of High-quality Custom Training Data for Language Models
High-quality training data is crucial for building effective and accurate language models. Language models are machine learning models that learn patterns and relationships in language data through exposure to vast amounts of text. The more diverse and relevant the training data, the better the language model will be at understanding and generating natural language.
Recently launched GPT-4 is a large language model that uses about 100 trillion parameters which is 500 times higher than GPT-3. These models have got a lot of training data from the web, books, etc but all data is not high-quality and have misformation in it. These models can produce misinformation and biased results.
To overcome these issues we generally do content moderation and remove biased or inappropriate content. But content moderation and review of data can solve misinformation and bias issues to some extent and make these models usable for uses like blog writing, summarization, etc. Recently Google launched their LLM Bard, which generate a wrong answer, and they lost $100 billion in market value.
If we want to do some specific tasks or fact-based tasks, we can not rely on the foundation model only, we need to train these models with specific domain high-quality training data to avoid misinformation and biased in the output. And for preparing high-quality training data you need experts and data partners who can create high-quality custom training data for an AI model.
Custom training data allow us to train our model for specific use cases which is not possible with a foundation model, it improves overall accuracy and reduces the chances of generating misinformation and bias.

12 Use cases of Language Model in 2023
Language models have a wide range of use cases across various domains, as they are designed to understand and generate human-like text. Some popular use cases of language models include.
Content Generation
Language models can generate high-quality content such as articles, blog posts, creative writing, or even poetry for various industries, such as marketing, journalism, education, and entertainment. They can be tailored to specific writing styles or tones, creating engaging and diverse content that captures the target audience's interest. Even in this blog, we have used a language model to generate some content.
Text Summarization
Language models can condense long documents into shorter summaries, making it easier for users to absorb essential information quickly. They can also generate different types of summaries, such as abstracts, extracts, or key point summaries, depending on the user's needs.
Sentiment Analysis
Language models can be fine-tuned to detect subtle emotional cues in the text, allowing businesses to analyze customer feedback, identify trends, and make informed decisions. They can also be applied to monitor social media sentiment and analyze public opinion on specific topics or products.
Machine Translation
Language models can support translation between numerous languages, including low-resource languages. They can be used for real-time translation services in communication apps, websites, or other platforms, allowing people from different cultures to interact seamlessly.
Chatbots and Virtual Assistants
Language models can be fine-tuned to understand domain-specific knowledge, enabling chatbots to provide accurate information and context-aware responses. This helps create a more human-like conversational experience in customer support, healthcare, travel, or other industries.
Question-Answering Systems
Language models can be used to build robust, domain-specific question-answering systems, such as medical diagnosis assistants, legal advice platforms, or educational tools, providing expert-like knowledge to users without requiring human intervention.
Text Classification and Tagging
Language models can classify text into categories like news topics, genres, or sentiment. They can also tag text with relevant metadata, such as keywords or entities, improving searchability and organization in content management systems or information retrieval applications.
Natural Language Processing Tasks
Language models can be adapted to perform various NLP tasks, like name entity recognition, part of speech tagging, semantic role labeling, or sentiment analysis, enhancing the accuracy and efficiency of text analytics and processing pipelines.
Code Completion and Generation
Language models can learn programming patterns, assisting developers in writing efficient and error-free code. They can provide context-aware code suggestions, generate boilerplate code, and even help debug or refactor existing code.
Personalized Recommendations
Language models can analyze user-generated text or browsing behavior, identifying preferences and interests. This can be used to provide personalized content, product recommendations, or targeted advertisements, enhancing user experience and engagement.
Email and Text Generation
Language models can automate email composition or draft text messages, adapting to individual writing styles and personalizing communication. This can save time for professionals who send frequent emails or help businesses craft more engaging marketing messages.
Speech Recognition
Language models can be integrated with speech recognition systems to improve transcription accuracy and context understanding. This enables voice-based interactions with devices or applications, such as voice assistants, voice-controlled home automation, or transcription services.
These are just a few examples of the numerous applications of language models. As technology continues to evolve, more innovative use cases will undoubtedly emerge.
Conclusion
As we have seen, language models have a wide range of use cases, including content generation, text summarization, sentiment analysis, machine translation, chatbots, question-answering systems, and many more. Their adaptability to different domains and industries has made them indispensable tools for businesses, researchers, and developers alike.
The training data used for language models play a crucial role in their performance. Large, diverse, and high-quality training datasets are essential for ensuring that these models are capable of understanding and generating accurate and relevant text across various contexts and languages.
Despite their remarkable achievements, language models continue to evolve, with ongoing research focused on addressing limitations such as data bias, energy consumption, and model interpretability. As these challenges are tackled, language models will become even more powerful, unlocking new possibilities for human-machine interaction and transforming the way we work, communicate, and access information.