What is a multimodal LLM?
Multimodel LLM
Text-to-Image
Image-to-Text
A multimodal LLM is a type of large language model (LLM) that can process, analyze, integrate, and generate multiple types of data such as:
- Text
- Images
- Audio
- Video
These models are trained on large datasets that contain various types of data and can perform a wide range of tasks, including but not limited to :
- Video analysis.
- Optical character recognition (OCR).
- Multimodal language translation.
- Generating images and videos based on text prompts.
In summary, multimodal LLMs have the potential to revolutionize various industries and applications, enabling more intuitive and human-like interaction between humans and machines. They can facilitate new forms of creativity, improve communication, and enhance decision-making. As the technology continues to evolve, we can expect to see even more innovative applications of multimodal LLMs in the future.
What Else Do People Ask?

Related AI Articles

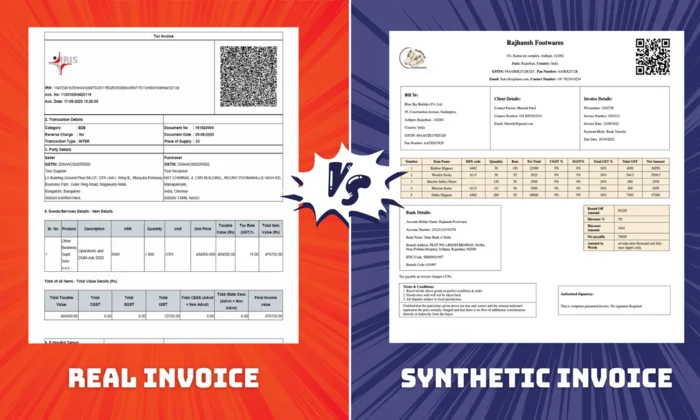
Browse Matching Datasets




Acquiring high-quality AI datasets has never been easier!!!
Get in touch with our AI data expert now!
