








We Use Cookies!!!
We use cookies to ensure that we give you the best experience on our website. Read cookies policies.
This OCR dataset consists of diverse types of images of sticky notes with handwritten text in the Tamil language. Along with images, this dataset consist of detailed metadata as well.
OCR & NER
2K+ images
Sep 2023
200+ people


Introducing the Tamil Sticky Notes Image Dataset - a diverse and comprehensive collection of handwritten text images carefully curated to propel the advancement of text recognition and optical character recognition (OCR) models designed specifically for the Tamil language.
Dataset Contain & Diversity:
Containing more than 2000 images, this Tamil OCR dataset offers a wide distribution of different types of sticky note images. Within this dataset, you'll discover a variety of handwritten text, including quotes, sentences, and individual words on sticky notes. The images in this dataset showcase distinct handwriting styles, fonts, font sizes, and writing variations.
To ensure diversity and robustness in training your OCR model, we allow limited (less than three) unique images in a single handwriting. This ensures we have diverse types of handwriting to train your OCR model on. Stringent measures have been taken to exclude any personally identifiable information (PII) and to ensure that in each image a minimum of 80% of space contains visible Tamil text.
The images have been captured under varying lighting conditions, including day and night, as well as different capture angles and backgrounds. This diversity helps build a balanced OCR dataset, featuring images in both portrait and landscape modes.
All these sticky notes were written and images were captured by native Tamil people to ensure text quality, prevent toxic content, and exclude PII text. We utilized the latest iOS and Android mobile devices with cameras above 5MP to maintain image quality. Images in this training dataset are available in both JPEG and HEIC formats.
Metadata:
In addition to the image data, you will receive structured metadata in CSV format. For each image, this metadata includes information on image orientation, country, language, and device details. Each image is correctly named to correspond with the metadata.
This metadata serves as a valuable resource for understanding and characterizing the data, aiding informed decision-making in the development of Tamil text recognition models.
Update & Custom Collection:
We are committed to continually expanding this dataset by adding more images with the help of our native Tamil crowd community.
If you require a customized OCR dataset containing sticky note images tailored to your specific guidelines or device distribution, please don't hesitate to contact us. We have the capability to curate specialized data to meet your unique requirements.
Additionally, we can annotate or label the images with bounding boxes or transcribe the text in the images to align with your project's specific needs using our crowd community.
License:
This image dataset, created by FutureBeeAI, is now available for commercial use.
Conclusion:
Leverage this sticky notes image OCR dataset to enhance the training and performance of text recognition, text detection, and optical character recognition models for the Tamil language. Your journey to improved language understanding and processing begins here.




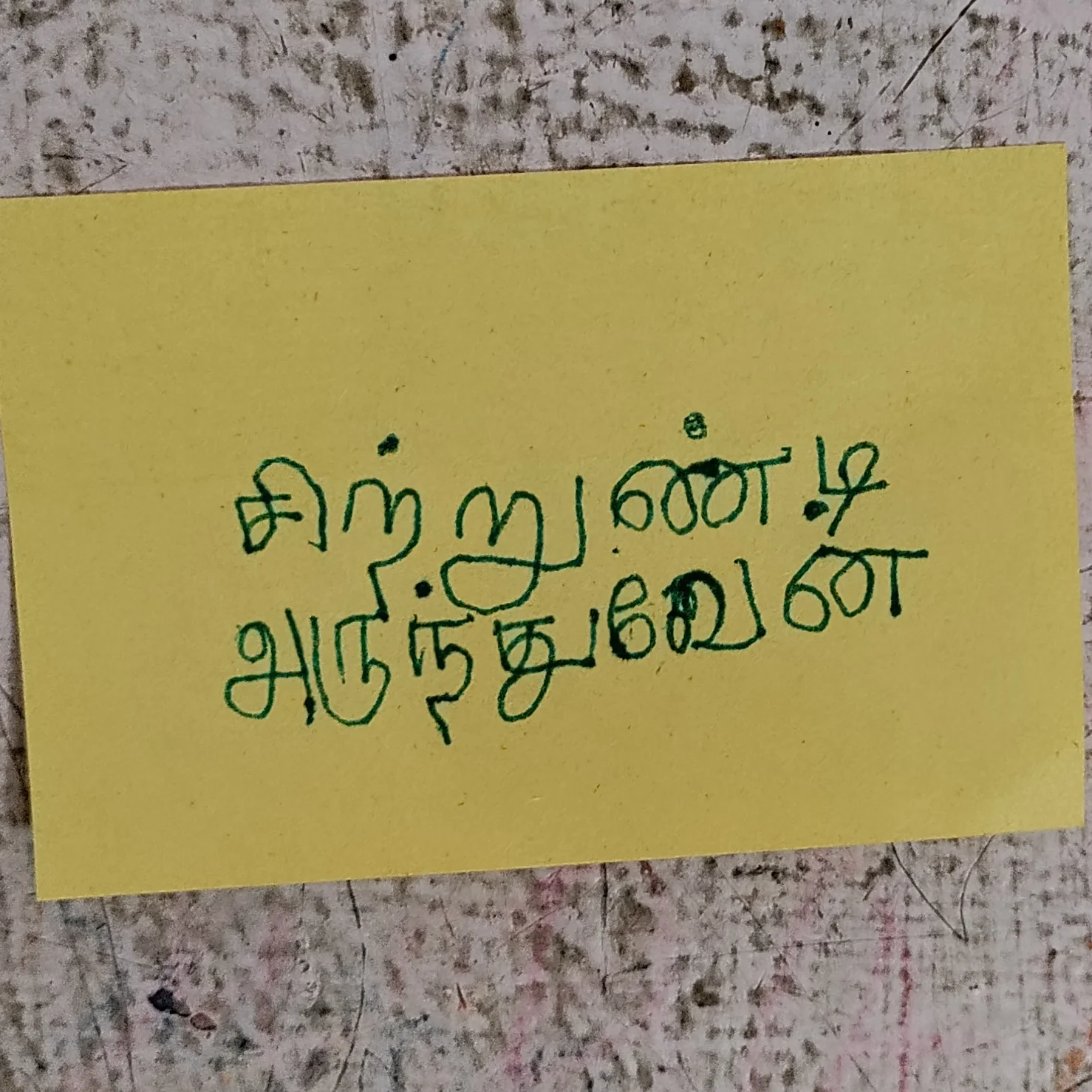





| Image Type | Sticky Notes |
|---|---|
| Image Orientation | Portrait |
| Language | Tamil |
| Country | India |
| Device Details | OnePlus-EB2101 |

Handwritten sticky notes
2K+ images
Image
Tamil
Diverse types
Indoor & Outdoor
Different lightening...more
JPEG, HEIC
Android & iOS
NA
Handwritten
Download a free sample of this dataset to get more clarity about this set! OR get in touch with one of our expert to get hands on experience 📨
Download Free Dataset

Contact Us
