

.webp&w=640&q=100)
.webp&w=640&q=100)
.webp&w=640&q=100)
.webp&w=640&q=100)
We Use Cookies!!!
We use cookies to ensure that we give you the best experience on our website. Read cookies policies.
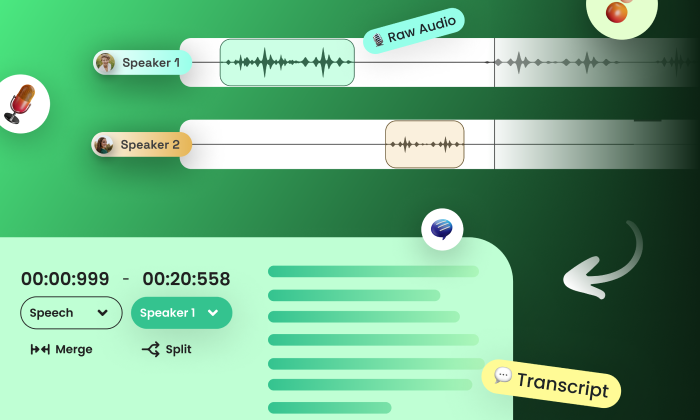
A speech dataset is a collection of audio recordings of human speech paired with their corresponding transcriptions, designed to train automatic speech recognition (ASR) systems effectively.
These datasets serve as crucial resources for training and fine-tuning speech AI models, such as ASR (Automatic Speech Recognition) and TTS (Text-to-Speech) models.
By encompassing diverse audio data featuring different accents, languages, and speaking styles, these datasets empower the development of robust and accurate speech AI models capable of understanding and generating human speech with high fidelity.
0.25x
0.5x
0.75x
1x
1.25x
1.5x
1.75x
2x

Get in touch with our AI data expert now!
