


We Use Cookies!!!
We use cookies to ensure that we give you the best experience on our website. Read cookies policies.


In our recent blog “guide on sample rate," we delved into the nitty-gritty of sample rates. Today, we're continuing our journey into the technical terrain by unraveling the mysteries of bit depth. Just like sample rate, bit depth plays a vital role in shaping the speech data that powers any speech AI application.
Now, buckle up as we demystify the science behind bit depth. We'll explore why it's a crucial factor, and most importantly, we'll guide you on choosing the right bit depth for your speech recognition needs.
But hey, before we geek out on bit depth, let's quickly refresh our memories with the ABCs of automatic speech recognition. Ready? Let's dive in!
Automatic Speech Recognition, or ASR for short, is a branch of artificial intelligence dedicated to the conversion of spoken words into written text. For an ASR model to effectively understand any language, it must undergo rigorous training using a substantial amount of speech dataset in that particular language.
This speech dataset comprises audio files recorded in the target language, along with their corresponding transcriptions. These audio files are nothing but recordings featuring human speech. These audio recordings should have consistent technical features as per the requirement to train the model and as discussed earlier bit depth is one of those very crucial technical features kept in focus while acquiring the training speech dataset along with other technical features like audio format, transcription format, sample rate, etc.
Now we have mainly two options to acquire training datasets for any ASR application;
1. Off-the-shelf commercial datasets or Open source datasets
2. Custom collection of dataset.
In the case of open-source or off-the-shelf datasets, it is essential to verify the bit depth at which the audio data was recorded. For custom dataset collection, it is equally vital to ensure that all audio data is recorded at the specified bit depth as per requirement.
In summary, the selection of audio files with the required bit depth plays a pivotal role in the ASR training process. To gain a deeper understanding of bit depth, let's delve into its intricacies.
In simple words, bit depth is nothing but the number of bits used to represent the amplitude of each sample in a digital audio signal. It quantifies the precision with which each sample is encoded, determining the range of values that can be assigned to represent the intensity or volume of the sound at a specific point in time.
The bit depth is measured in the unit of bits and some of the common bit depths used in regular life cases are 16 bit, 24 bit, or 32 bit.
Now that we know the basic definition of bit depth let’s understand it even better with the Quantization process.
In the process of training ASR models, the initial step involves the conversion of analog signals to digital form through analog-to-digital conversion (ADC). Following this conversion, the digital representation undergoes a quantization process, wherein the audio signal is mapped to binary values, typically denoted as '0' and '1'. This procedure is formally known as the Quantization process.
This means each bit has two possible values 0 and 1. So if we have a bit depth of 2 bit that means we have a total of 2^2 = 4 quantization levels available to represent the audio sample. For this bit depth of 2 bit the binary notations are like this [0,0], [0,1], [1,0], [1,1].
Now if we have a bit depth of 4 bits that means we have a total 2^4 = 16 quantization levels available to represent the audio sample and these levels can be represented with binary notation like [0,0,0,0], [0,0,0,1], continue to [1,1,1,1]
Similarly bit depth of 16 bits provides us a total of 2^16 = 65536 values for representation and the binary notation starts with [0000000000000000] and ends at [1111111111111111].
So we can observe one thing here the more the bit depth the more the quantization levels we have to represent the audio samples. Now let’s understand what these quantization levels mean and how it is important.
Let’s imagine we have an audio signal of let’s say human speech which looks something like this on the graph.
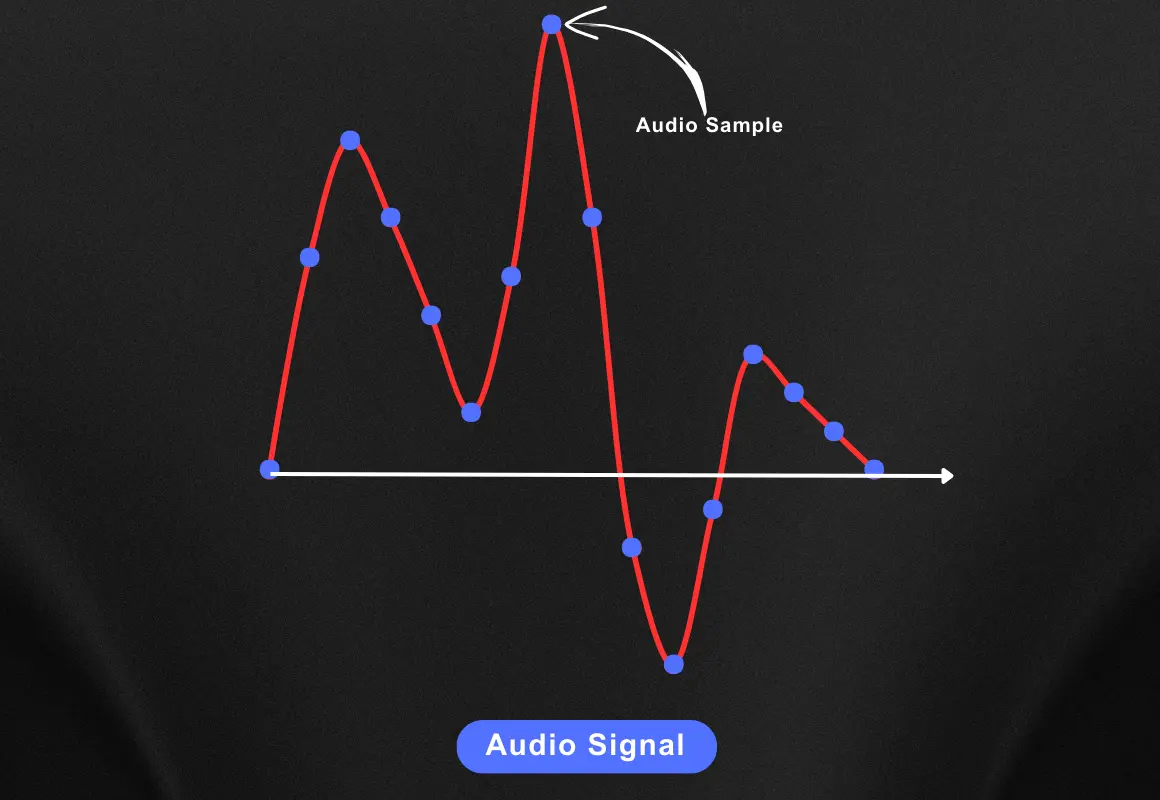
If you have checked our last blog on sample rate you know that these blue dots represent the sample and the number of such samples per second represents the sample rate.
Now let’s say we have a bit depth of 2 bits and as discussed earlier in this case we have 2^2 = 4 quantization levels and these levels are represented with the white dotted line in the below the image
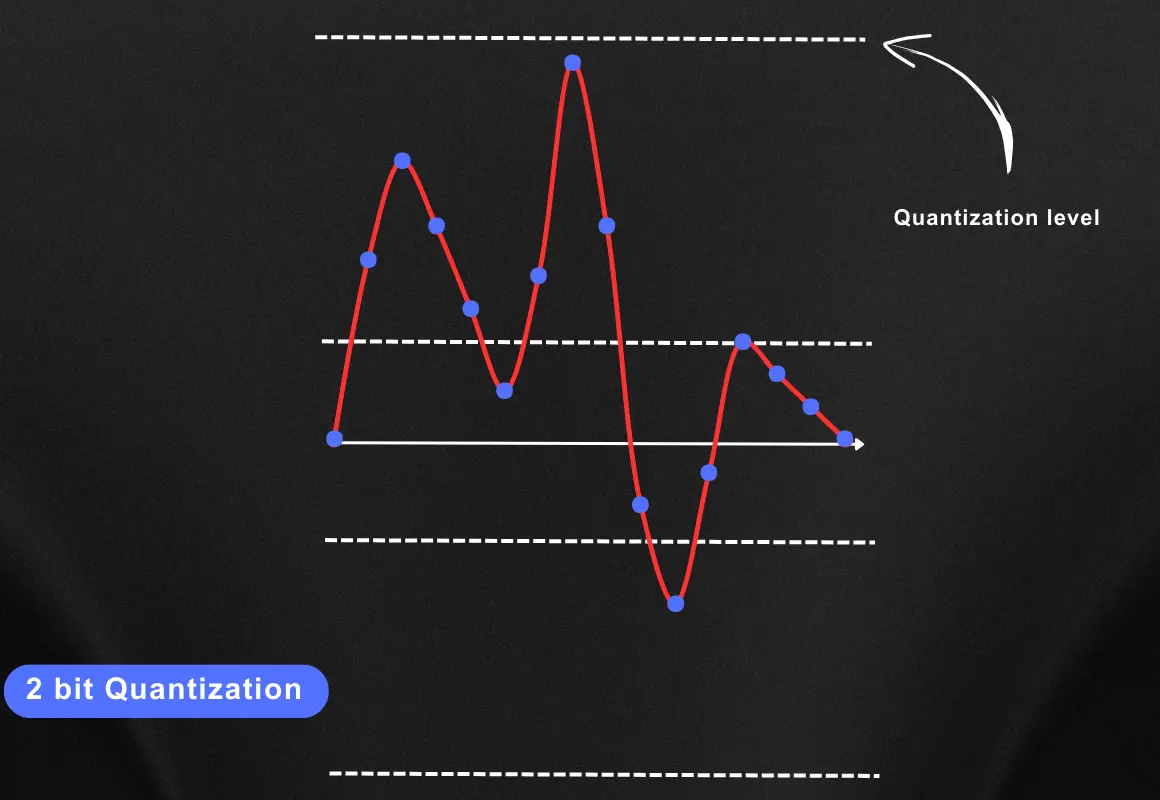
Quantization is more like rounding off the samples to the closest quantization level and in this case, this rounding off will look something like this.
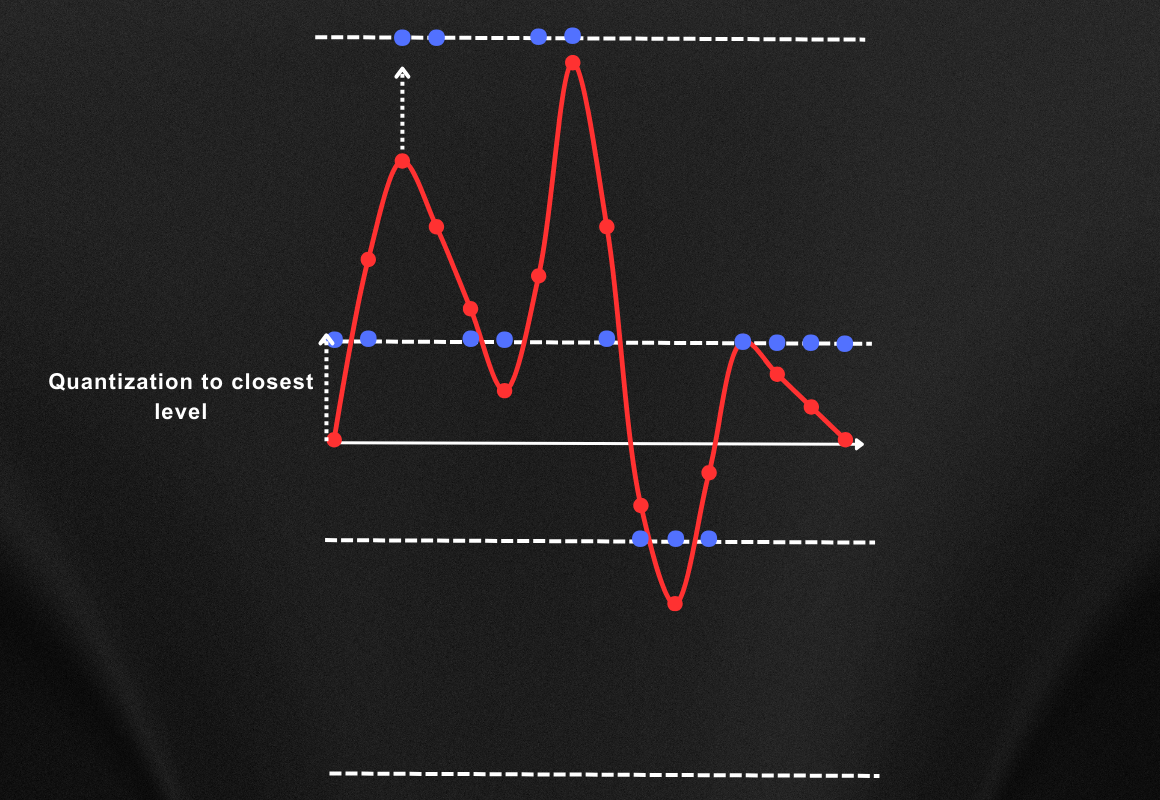
Now if we connect these round-off samples the new produce a new audio signal then it will look like the yellow graph shown in the below image.
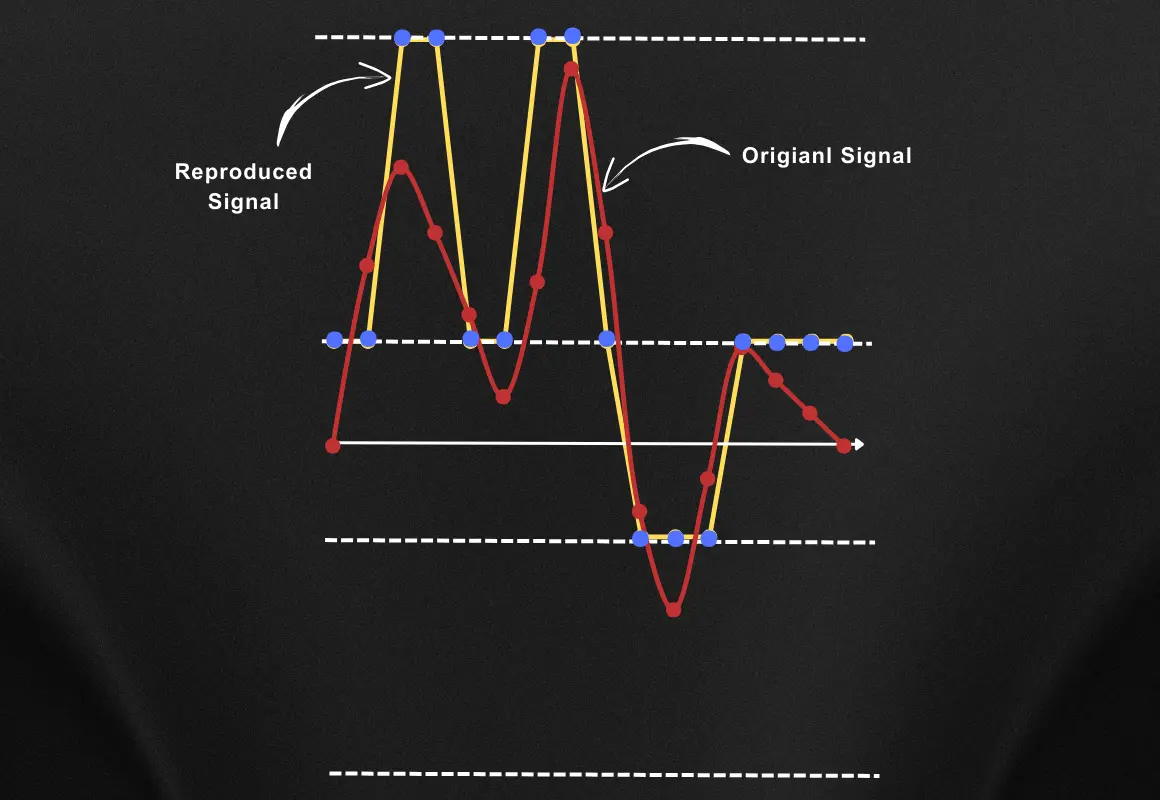
Now let’s compare both the audio signals, the original one and the reproduced one. You can see the comparison below.
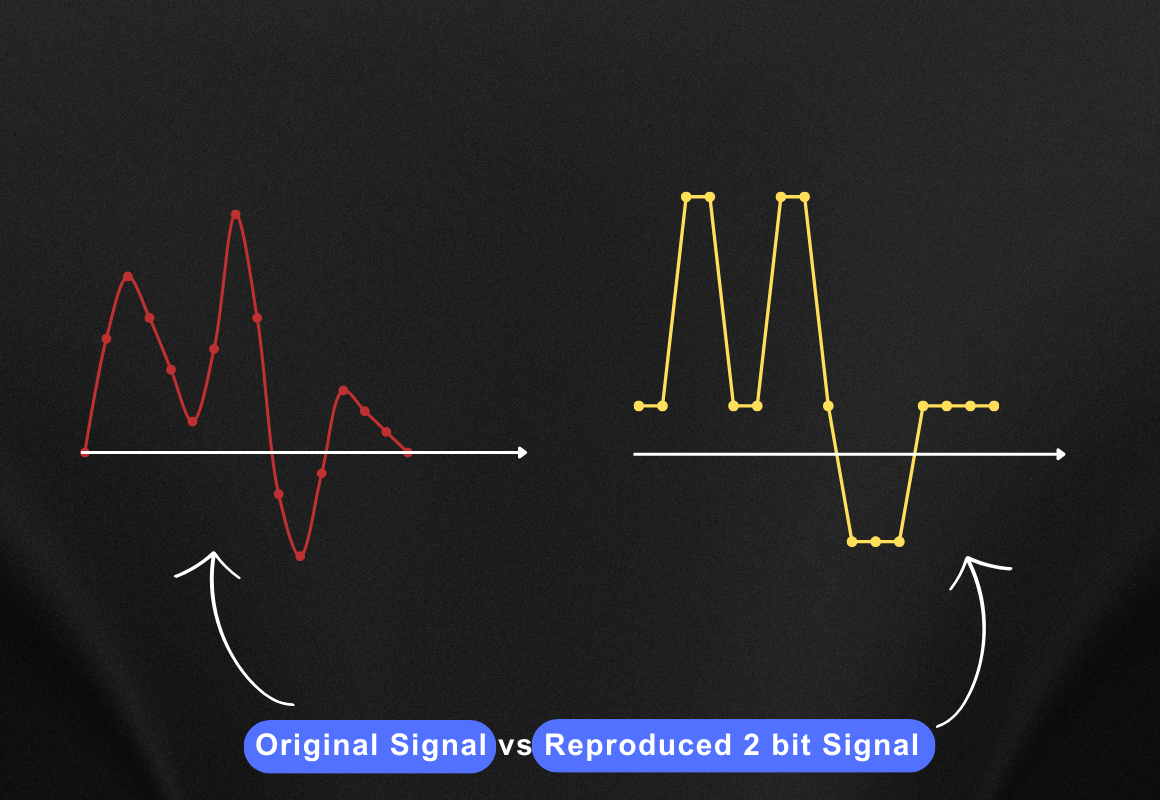
As you can see the reproduced audio looks somewhat similar to the original audio signal but not a very good representation of the original one, right?
Now let’s say we have a bit depth of 4 bits. The quantization levels are denoted in the below image with white dotted lines. You can see a total of 2^4 = 16 quantization levels in this case.
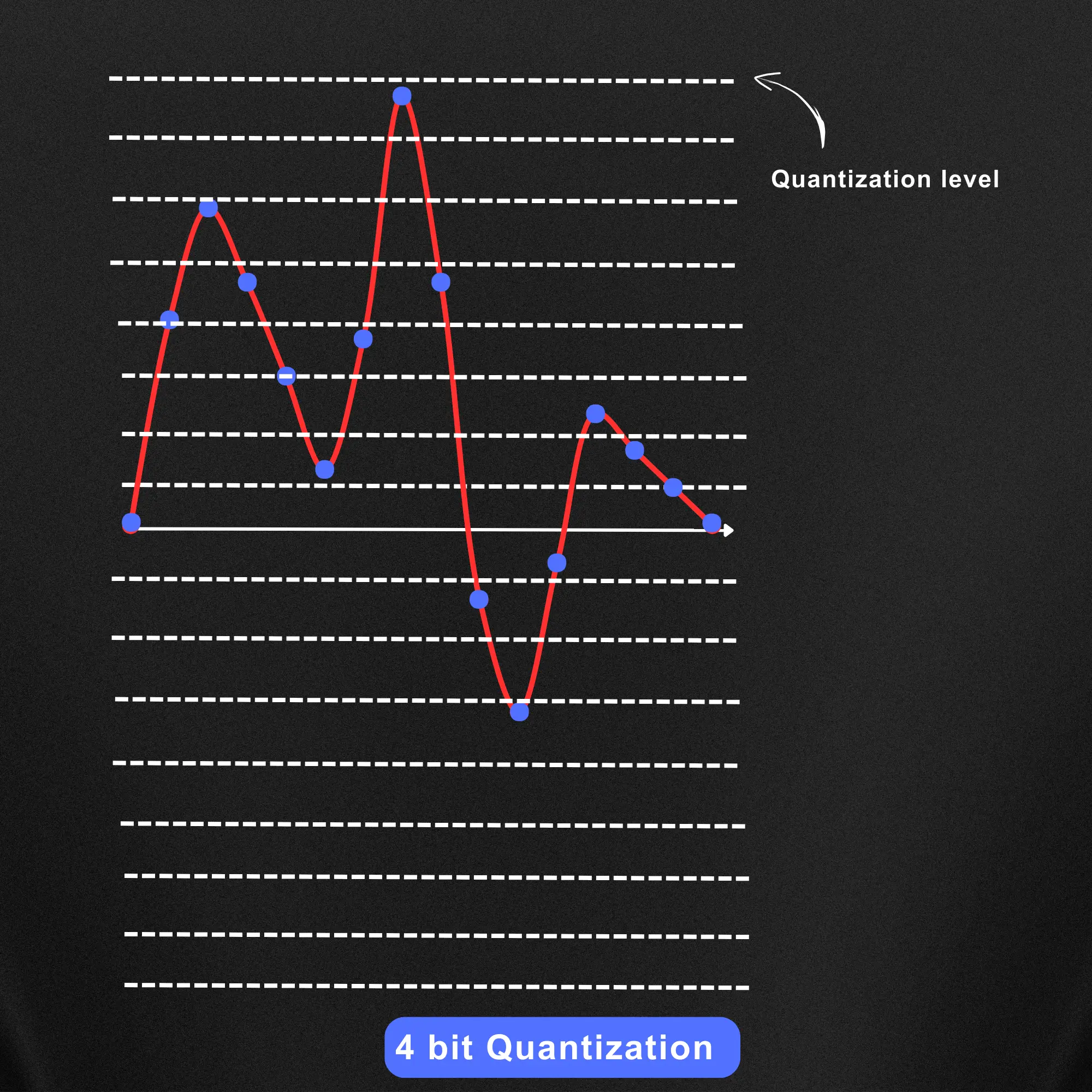
Now in the case of a bit depth of 4 bit the quantization of the audio sample to the closest level will look something like this.
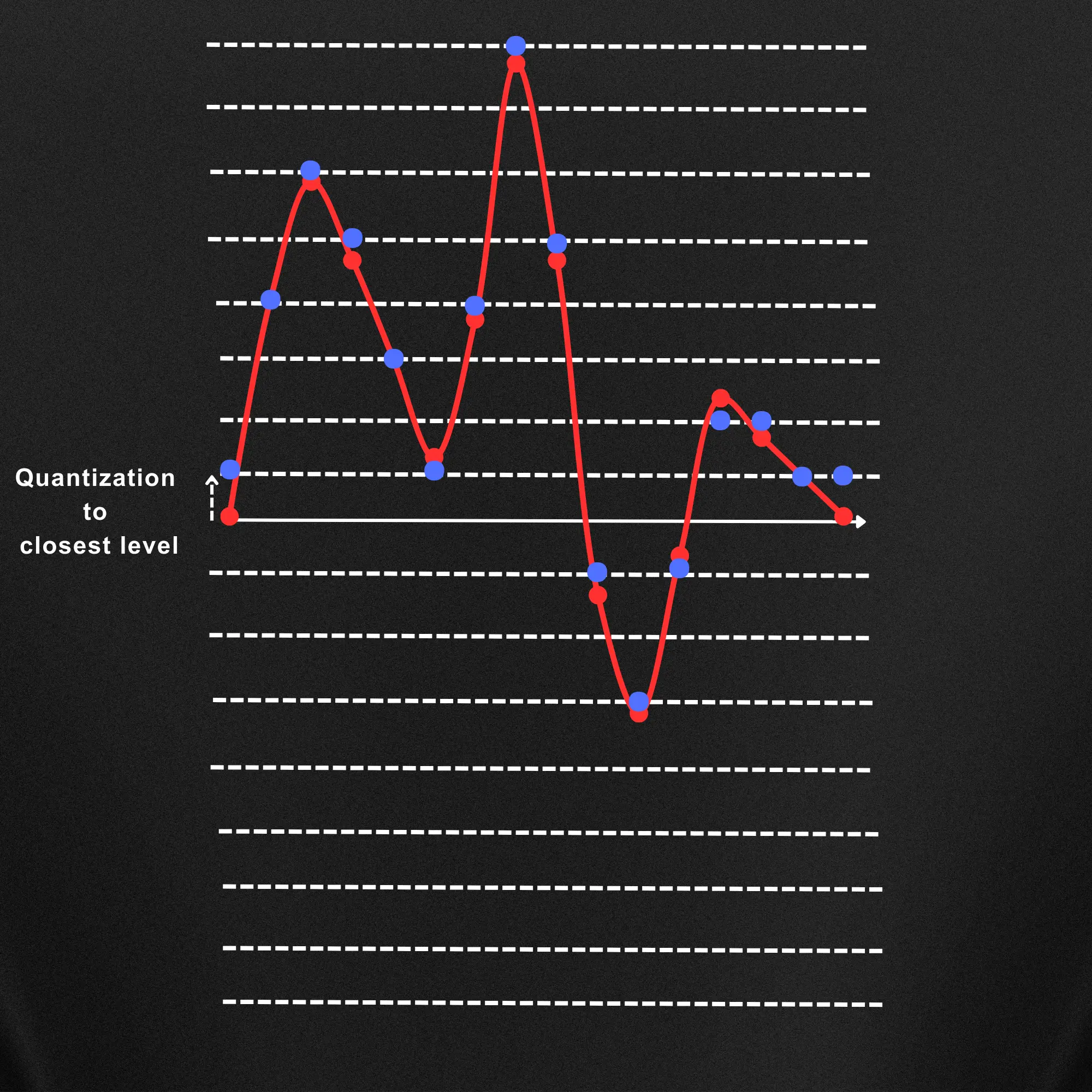
When rounding off the samples to the closest quantization level and connecting the sample dots the reproduced audio signal will be like the yellow audio graph shown below.
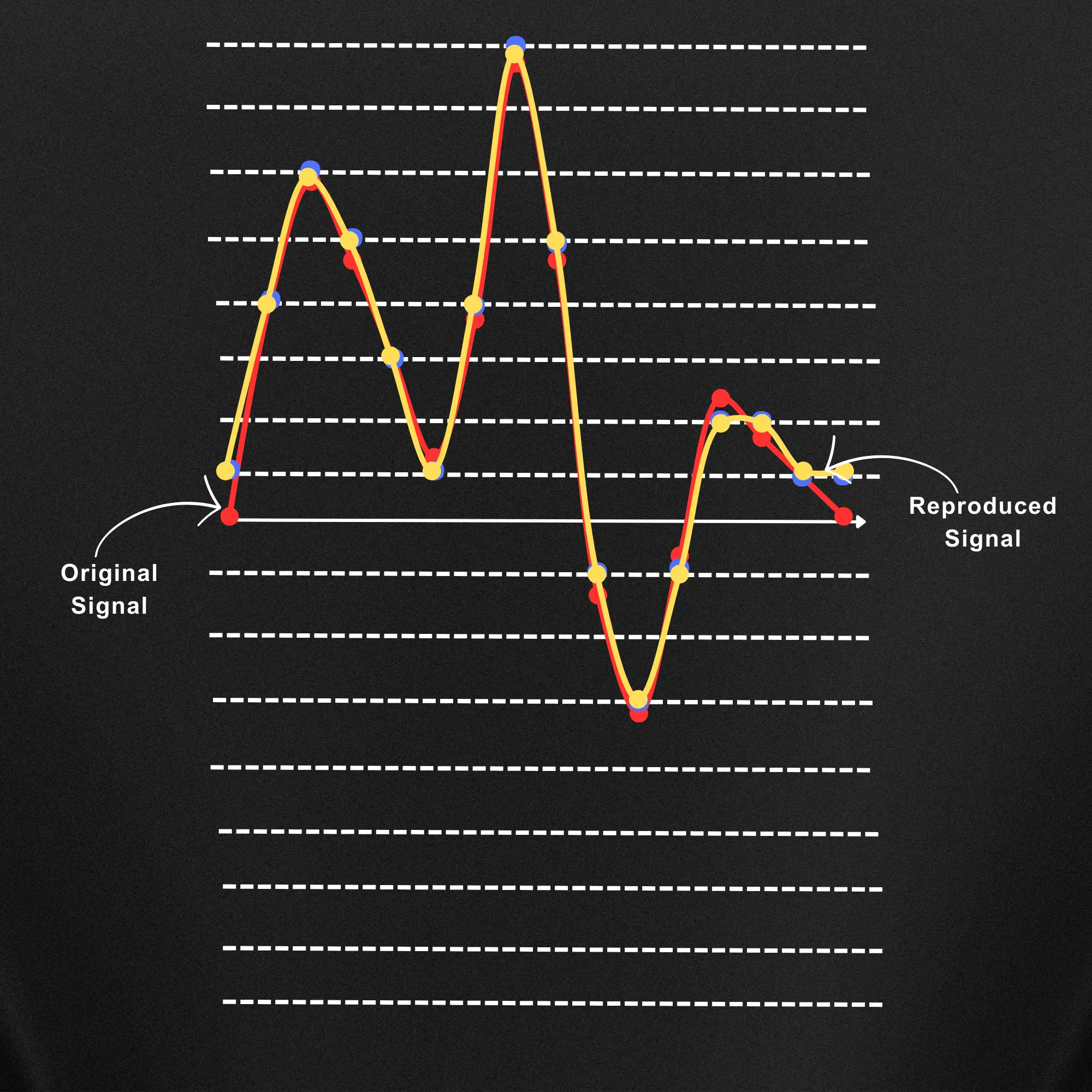
Now let’s compare the original signal and the reproduced signal with the bit depth of 4 bit.
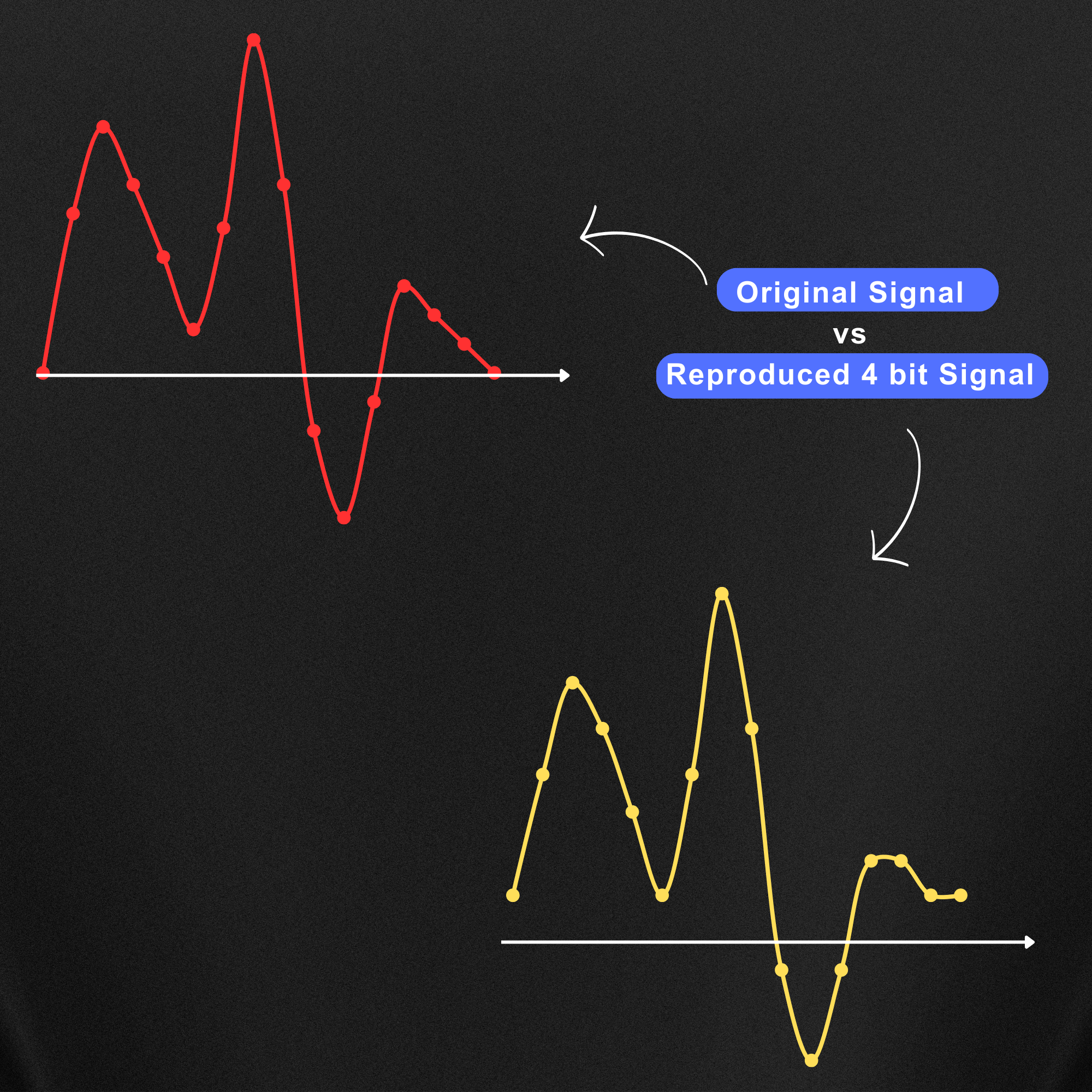
Now as you can see the original and the 4-bit reproduced signal are identical. If you also compare the reproduced audio signal graph in the case of 2-bit and 4-bit, obviously the 4-bit is a way better and more accurate representation of the original audio.
Now just imagine if we have audio with a bit depth of 16 bits we will have such 65536 dotted lines (quantization levels) and the reproduced audio will be much clearer compared to 4 bits as we now have an even closer level to round off the sample which will reproduce very accurate audio signal.
From this exercise, we can observe that the higher the bit depth the more accurate and high-quality audio signal we can produce. Also with the higher bit depth, you can capture a dynamic range in audio which refers to the softest and loudest sounds in a piece of music or a sound recording. It represents the span of volume levels from the quietest to the loudest.
Higher bit depths provide more quantization levels, allowing for finer gradations in the representation of amplitude. The additional quantization levels in higher bit depths allow for the representation of subtle nuances in audio, including quiet sounds or low-level details that might be lost in lower bit depth representations.
So our first instinct says we should choose the highest bit depth but that’s not the case. With higher bit depth there are some challenges as well and they are as follows.
Higher bit depths result in a more precise representation of audio, but this comes at the cost of increased file size. Storing and transmitting larger files can be resource-intensive.
Processing audio with higher bit depths requires more computational power. ASR systems may experience increased processing demands, affecting real-time performance and responsiveness.
Some systems or devices may not fully support or be optimized for higher bit depths. Compatibility issues can arise when trying to use or share audio data with higher bit depths across different platforms.
The perceptual improvement in audio quality may not be proportional to the increase in bit depth. Beyond a certain point, the human ear might not readily perceive the additional detail provided by higher bit depths.
Storing audio data with higher bit depths can result in increased storage costs, especially when dealing with large datasets. This may be a concern in scenarios where cost-effectiveness is a priority.
ASR systems may not experience a proportional improvement in accuracy with higher bit depths. The benefits of increased precision may not be as significant in ASR applications compared to certain audio production scenarios.
In many ASR applications, the practical benefits of very high bit depths may be limited. ASR often focuses on extracting relevant features from the audio, and excessively high bit depths might provide more information than necessary for the specific tasks involved.
Choosing the right bit depth for various use cases of Automatic Speech Recognition (ASR) involves a nuanced decision-making process. It's crucial to strike a balance between audio quality, computational efficiency, and practical considerations.
Understanding the basics of bit depth and its impact on audio quality is a foundational step. Consider the nature of the speech signals; since ASR primarily deals with linguistic information from speech, excessively high bit depths may not yield significant benefits for typical speech scenarios.
Balancing precision and practicality is key, and a common choice is 16-bit, offering a good compromise. A 16-bit bit depth provides 2^16 (65,536) possible quantization levels. This level of precision allows for a sufficiently detailed representation of audio signals. The dynamic range afforded by 16 bits is often deemed satisfactory for capturing the nuances of speech, including the variation in volume and tone.
In terms of computational power, transmission, storage requirement and precision 16 bit offers the most reasonably accurate output. This is the reason why 16-bit is preferred for a range of use cases like speech recognition, conversational AI, or text-to-speech.
The use of 16-bit audio has become somewhat of an industry standard for speech-related applications. This standardization simplifies interoperability and ensures a consistent approach across different systems and technologies.
While 16-bit audio may not be the absolute maximum in terms of precision, it strikes a well-accepted balance that satisfies the needs of various speech-related applications, making it a pragmatic and widely adopted choice in the industry.
We at FutureBeeAI assist AI organizations working on any ASR use cases with our extensive speech data offerings. With our pre-made datasets including general conversation, call center conversation, or scripted monologue you can scale your AI model development. All of these datasets are diverse across 40+ languages and 6+ industries. You can check out all the published speech datasets here.
Along with that with our state-of-the-art mobile application and global crowd community, you can collect custom speech datasets as per your tailored requirements. Our data collection mobile application Yugo allows you to record both scripted and conversational speech data with flexible technical features like sample rate, bit depth, file format, and audio channels. Check out our Yugo application here.
Feel free to reach out to us in case you need any help with training datasets for your ASR use cases whether that be dataset collection, annotation or transcription. We would love to assist you!
