



We Use Cookies!!!
We use cookies to ensure that we give you the best experience on our website. Read cookies policies.


We all know that AI has enormous power to build unique human-like solutions, and we can see AI and ML models replacing human assistance in many domains! Any AI or ML model consists of basically two things: one is data, and the other is a model. Experts in the AI ecosystem frequently refer to data as an ingredient and model as recipes, or data as food and model as body. Both go hand in hand, and neither functions in isolation!
Our goal with building AI solutions is to build intelligent machines that efficiently perform that specific task, but in real-world execution, that machine learning model has to deal with lots of variables and diversity. To build such a robust AI solution that works for everyone, extensive training is the key! In order to do so, we need to feed lots of data with all possible features, circumstances, and occurrences. This collection of extensive data is often referred to as "AI data" or a "dataset!"
In this article, we will cover almost everything that one should know about datasets, types of datasets, and variations of datasets!
We can define an AI dataset as a collection of diverse sets of information in digital form that contains all the variables for a machine learning model. Similarly to humans, machines also learn from past data, so we can define a dataset as a collection of past experiences in the form of data.
In any AI model development or machine learning process, the first couple of steps are to identify the potential uses of the solution we are building, the users who are going to use it, and their variables, and through these steps, we understand what kind of data we need to train the model. It’s called the requirement identification stage. Every unique solution needs a unique dataset to train the model. Acquiring an adequate dataset can be a very crucial aspect. It can save lots of time and money if this decision is made accurately.
It is very crucial to understand AI datasets, different types of datasets, and their importance in each stage of the model development process in order to clearly understand how any AI model actually works.
Depending on the use case and model, datasets can take various forms. For the speech recognition model, unscripted speech conversations will be AI data. For computer vision, specific images and videos will serve as the needed AI data. Parallel corpora can be AI data for machine translation engines. For voice assistants and voice bots, scripted monologue commands will be the AI data. It simply means AI data can be in various forms, like images, videos, speech, or text, depending on the type of AI model you are building.
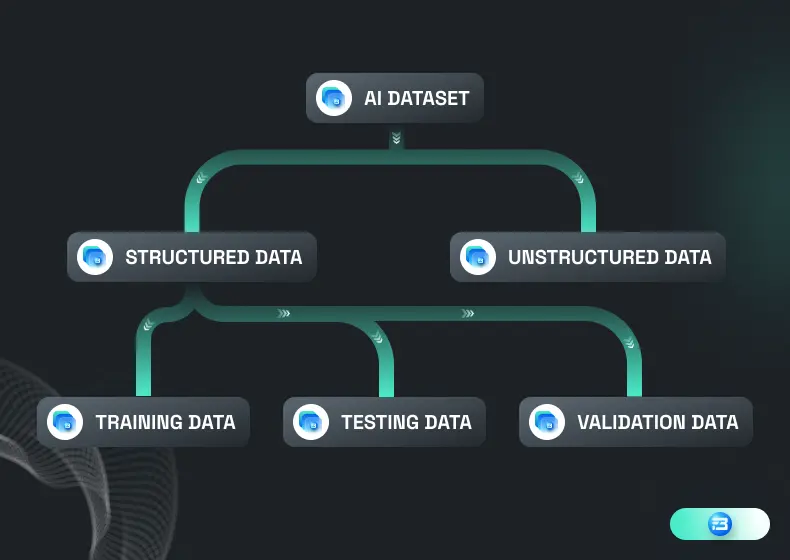
Apart from different forms of dataset like image, video, speech, and text, we can also divide datasets into two logical parts: structured and unstructured datasets. The term "structured" refers to a dataset that is in its final form and can be used in our machine learning process, as the name implies. A structured dataset is a collection of logical, diverse, unbiased, and labeled data that is ready to deploy for the training of any machine learning model.
On the other hand, an unstructured dataset can be defined as one that is currently in raw format, which means it has not been cleaned or labeled. An unstructured dataset is the initial stage of any dataset preparation process. It needs to pass through various stages of the process, like cleaning, labeling, and reviewing.
Let’s understand it with the case study:
One of our clients, a leading company in the space of computer vision technology, was building an AI-enabled vision solution that keeps track of employees and workers in the manufacturing unit. The purpose of building this is to check if the workers are equipped with a PPE kit or not and ensure the safety of their work unit. Through this CV model they want to track various objects like helmet, gloves, vest etc.

The structured dataset for this particular problem is image or video data from manufacturing that contains all the variations, like workers wearing, not wearing, or partially wearing PPE kit. All these variations are required to make sure that the model can perform perfectly in real life.
In this case, they already have the data in the form of security camera footage, but it cannot be used directly to train the machine as it is in an unstructured format. We help them convert this unstructured data into a structured dataset for their computer vision model through the following stages:
 We convert the video footage into frame-by-frame images.
We convert the video footage into frame-by-frame images.
We removed blurry images, which are not useful for models
We removed frames that don’t contain any related information. Frames where workers are not there in the frame.
We then annotate each image with all required labels, like human, helmet, gloves, and vest, through bounding box annotation.
An unstructured dataset can be a collection of available raw data at the initial stage of data preparation, but in order to use that to train our model, we eventually have to convert it into a meaningful form for our model, which is called structured data.
People also refer to the structure dataset as a "training dataset," as it is being used in the entire AI model training process. The AI model training process is also divided into various stages like training, validation, and testing, and for each stage we need a different dataset.
For this purpose, we divide the entire training dataset into three different parts: the training dataset, the validation dataset, and the testing dataset. This is referred to as a "training dataset split."

A training dataset is a collection of data that contains all important features related to that specific task, and on this dataset the machine learning model is being trained. This is also referred to as an input dataset. For the validation datasets, a portion of this training dataset is extracted.
The validation dataset has its own unique purpose: to test the model's fit while tuning hyperparameters. To understand this, we can say the model is being trained on an 80% training dataset, 20% of which is taken out for a validation dataset, and then we validate the model on that 20% validation dataset. In the next iteration, another part of the training dataset should be taken out as a validation dataset, and the model is being trained on the remaining dataset. Once it's done, the trained model should be validated on this new 20% validation dataset. This method is called cross-validation. The number of iterations depends on the model, complexity, use case, and methods.
The sole purpose of the validation dataset is to find the model with the best accuracy. But sometimes this result can be biased as the validation dataset is part of the training dataset and the model is already trained on similar features.
The test dataset is kept aside until we have the final model in hand. Once we have our final model, we test that model with our test dataset. The test dataset is a highly customized and well-curated dataset. It generally contains all the scenarios and data points that the model is going to face in the real world. It is used to judge how accurately trained models will perform in the real world.
So each part of this dataset has its own unique purpose, and once a model is accurately trained and tested on such a dataset with the optimum accuracy level, we can say that such an AI model is ready to serve people in the real world.
From our conversation till now, it appears that the training dataset has lots of technicalities to deal with. As artificial intelligence is not a code-based program, and as it builds patterns and understands the world through the data we feed it, human-in-the-loop is very important while building any AI solution.
To build ethical AI solutions, the development team has to be clear about the requirements, area of complexity, features to deal with, and associated criticalities. Our decision to transfer human-involved tasks to a machine is not as simple as it seems. Such complexity makes a human intervention in the entire flow of the model development process very crucial.
Starting from collecting data to annotation to training to deploying machine learning solutions in real life, human-in-the-loop plays a vital role. Procuring quality datasets and making sure that the dataset qualifies on each parameter of accuracy, completeness, reliability, relevance, and timeliness is a task that needs continuous human attention. Some AI-asserted solutions need synthetic datasets, as acquiring real-life datasets can be complex, time-consuming, or expensive. In designing and building synthetic datasets, we also need human assistance.
Having a team of domain experts can take you way ahead and help you scale your AI development process really fast. Building and training an expert team for dataset and annotation is not at all easy, and it takes lots of time and experience to get to that stage. That is why leading AI organizations trust the FutureBeeAI crowdsourcing community for all the solutions revolving around datasets and model training.
Following this discussion, we realized that the success of any AI or ML model is highly dependent on the quality of the data. The popular saying "garbage in, garbage out" works here as well. The quality of the data used for training any AI model will heavily influence its output.
According to dimensional Analysis research, up to 96 percent of organizations have issues with training data, both in terms of quality and quantity. These organizations are unable to acquire datasets with the required quality parameters and in enough quantity to train the model accurately. That means choosing the right data enabler can get you half a win.
Obsessed with helping AI developers over 5 years in the industry, we here at FutureBeeAI thrive on world-class practices to deliver solutions in every stage of AI dataset requirements, from selecting the right type of data and structuring unstructured data to stage-wise custom data collection and pre-labeled off-the-shelf datasets.
We hope you received an answer regarding training data knowledge for AI development!
Book a call with our data acquisition manager for spam-free advice right now!
