


We Use Cookies!!!
We use cookies to ensure that we give you the best experience on our website. Read cookies policies.


Data is everywhere around us in all possible forms and sizes. Every action we take online generates data, including sending emails, Tweets, IoT messages, and uploading videos to YouTube. Every day, we generate approximately 2.5 quintillion bytes of data, which is part of “big data." Every day, approximately 720,000 hours of video are uploaded on YouTube. This video data can be a good source of speech data for automatic speech recognition applications. But the question is, can we use it? The answer is no! because it is not a structured dataset!
To train an AI model for a specific task, we need quality structured data. It can only see the world as far as it has been trained to see it. You must have realized that even one of the extensive chat-based AI solutions, Chat GPT, went blank in so many scenarios. Why does that happen? The answer is simple: It's not trained for that particular prompt. So, how much data is needed for any model to work flawlessly all the time is a very critical question, and there is no sure-shot answer to that.
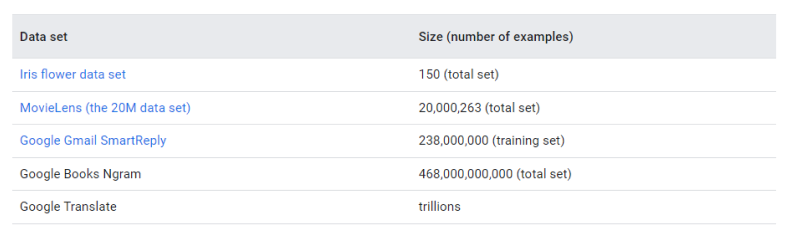
It is generally seen that simple models with large datasets beat fancy models with smaller datasets. Building a model for a simple use case like identifying a flower may need a couple of thousand sets of data, but creating a machine translation engine like Google Translate needs trillions of sets of data. But the concept of "the more, the better" cannot work in isolation. The size of the dataset may vary according to the use case, but quality should remain intact.
The quality of any AI model highly depends on the training data fed into it. To build a robust AI model through a supervised learning approach, we have to train it on high-quality datasets. It simply suggests that having a huge volume of data will serve no purpose if it’s bad data.
Now the question we have is: What is quality data? How to define this term? In layman's language, we can say that a dataset that serves our purpose can be a quality dataset. A dataset that accomplishes the given task is a quality dataset. But we can’t survive with this rough definition.
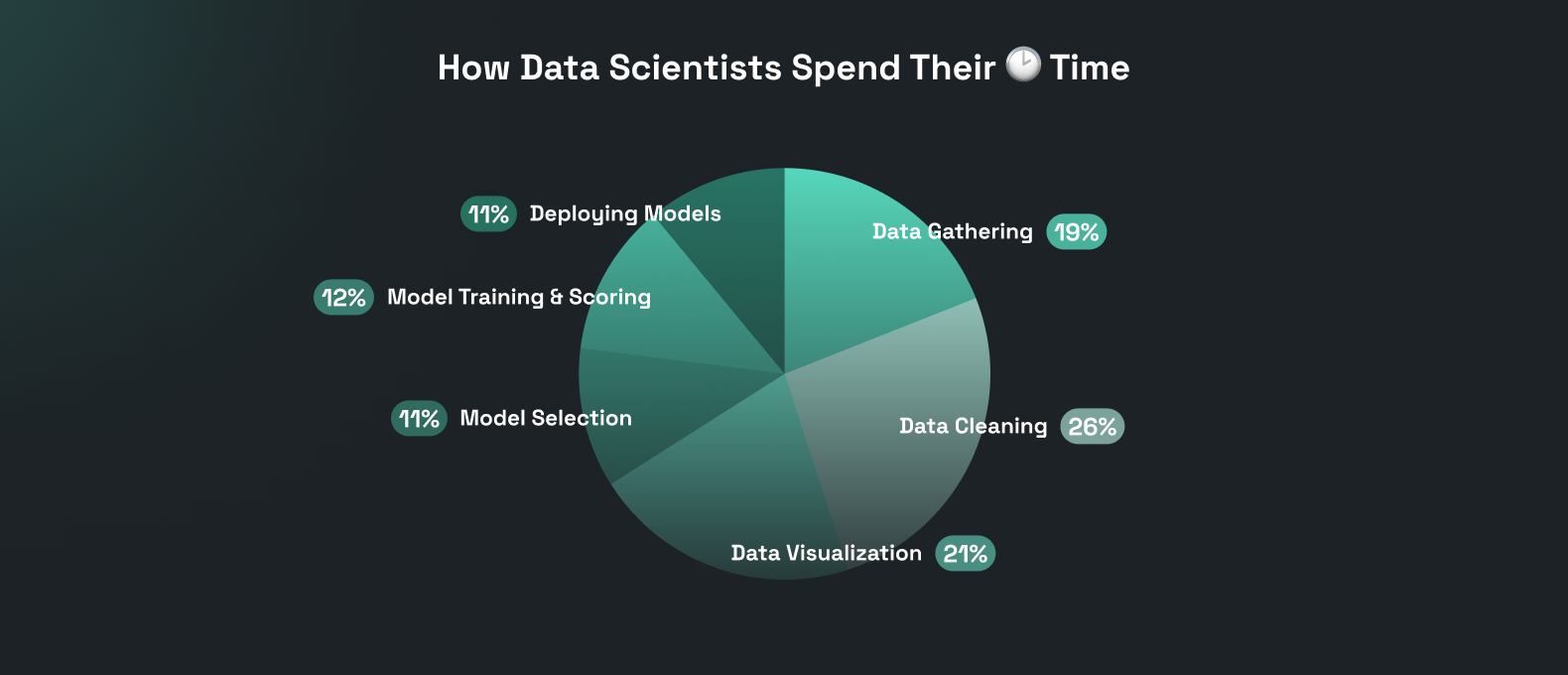
As a developer, you must be clear about what you are expecting out of a quality dataset, as a survey suggests that data scientists spend 45% of their time in the data preparation and having a high-quality dataset is a crucial step and it can influence the performance and accuracy of AI models to a great extent!
In this article, we will uncover some of the most important characteristics of a high-quality dataset. You will be amazed at how each parameter can affect the accuracy of any AI model. We will explore each one with real-life examples. So let’s get started.
To achieve better-performing models that serve a global audience unbiasedly, we must consider certain dataset characteristics when acquiring the dataset. Some of these characteristics are listed below.

As the name implies, one of the most important aspects of any dataset is its accuracy. An accurate dataset is one that is full of valid context about a particular task. It means an accurate dataset contains all the useful parameters, and all those parameters are well annotated with no errors.
The accuracy of a dataset is defined by how well the model can be trained and how accurately it can predict for that specific use case using such a dataset. Accuracy can be achieved through accurate collection and quality annotation. It is seen that low-quality annotation can lower the overall accuracy of a dataset, and such datasets cannot serve the purpose of building robust AI algorithms.
In a recent analysis of MIT, it was concluded that human annotators have mislabeled many images with one breed of dog with another, mislabeled the sentiments of many positive reviews as negative. Almost 20% of ImageNet photos have multiple objects in them, which makes it a bit complex for unskilled annotators to label them accurately, which drops the accuracy of models by around 10% when trained on such a dataset.
To procure an accurate and reliable dataset, we need skilled, trained, and unbiased annotators, as it is often seen that human annotators bring their own biases and shortcomings to the table.
Key Action: To make sure that the dataset is accurate and reliable, we must be clear about all important parameters, annotation types, labels, and potential dilemmas of annotators. It helps in the proper training of annotators to ensure that the dataset that we are producing is unbiased and accurate.
A comprehensive dataset is one that contains data for all possible parameters, scenarios, and circumstances. While building a global AI solution, we must be sure that the dataset is comprehensive to the extent that it contains the data for edge use cases as well.
On the other hand, we have to make sure that the dataset we are creating for a particular use case contains only relevant information. The dataset's relevancy is just as important as its comprehensiveness. Irrelevant or unnecessary data in a dataset can lead to more time consumption in each stage of data preparation, which eventually leads to higher costs.
It is often observed that AI models generally perform poorly if trained on a dataset that doesn’t contain all the parameters related to all possible circumstances.
In one of the studies published by Google and the University of California, Los Angeles, it was observed that there is "heavy borrowing" of datasets in the machine learning field. which means there is heavy adoption of publicly available and very limited datasets created by prestigious organizations. Each AI solution is unique and needs a unique dataset specific to the use case. Along with that, it needs to be annotated for that particular use case.
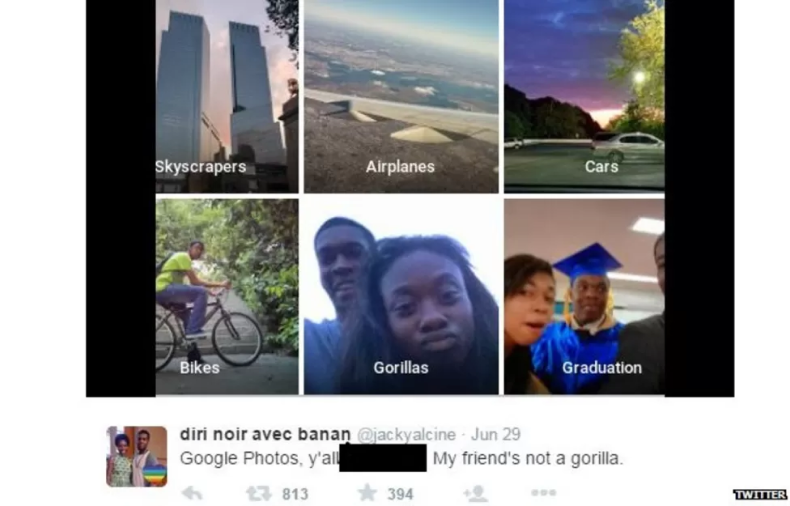
These publicly available datasets may not contain all of the parameters and data required for your AI use case. It is evident from many past cases that AI algorithms malfunction due to being trained on such flawed, irrelevant, and non-comprehensive datasets. A software engineer pointed out a flaw in the image recognition algorithm of Google Photos that was labeling his raced people as "gorillas."
It is important to note that if the model is being trained on too much, irrelevant or inaccurate data, it can lead to overfitting of the model. which means the model will only perform well on the training dataset but poorly on new data in real life.
Key Action: We must be aware of the use case, potential users, and all the possible information regarding it. It can help us identify and focus on only the important parameters we need in our dataset. Extensive research and enough knowledge about the market and users can give us an advantage in creating a dataset that is comprehensive enough to train our AI algorithm.
Diversity is also one of the key matrices for a quality dataset. A diverse dataset is one that can be used to train AI models for users based on all of your targeted demographics and user profiles. A dataset must accurately reflect the entire user base of that AI solution.
Before training a model on any dataset, we have to make sure that the dataset is not biased toward any particular user profile or demographic. A quality dataset is one that has a uniform distribution of data across all user profiles.
Such a biased and constrained dataset can lead to "biased AI," which will consistently give different results and outputs to one group of people. Often, datasets are biased based on age, race, gender, and nationality, and such datasets create an AI that follows the same societal biases.
One recent study published by PNAS in 2020 underlines the fact that some of the best SOTA (state of the art) speech recognition models by leading technology companies are biased toward black speakers. It was observed that while transcribing structured interviews, the average word error rate (WER) for black speakers was 0.35 compared to 0.19 for white speakers. It signifies that such speech recognition systems are almost twice likely to transcribe audio incorrectly for black people compared to white speakers.
In addition to racial bias, many AI applications are gender biased. One of the studies conducted by the University of Washington concluded that YouTube’s automatic caption generator is less accurate for females.
Key Action: Once we have a clear persona of all our potential users, we have to make sure that we collect data uniformly for all the user profiles. This uniformity should be across age groups, genders, accents, languages, and nationalities.
This is a very obvious but equally important feature that should be present in any high-quality dataset. Our goal with the feeding dataset is to train the algorithm, not confuse it, right? For that sake, we need a uniform and consistent dataset for training.
Data uniformity means all the parameters and corresponding labeled attributes are uniform across the entire dataset. For example, two different annotation teams are labeling images for object recognition use cases. One team labels the object "bottle," and the other team labels a similar object "sipper." Deploying such a non-uniform dataset can cause trouble during model training.
Acquiring datasets from different internal and external sources can be one of the factors affecting the uniformity of a dataset. Such data acquisition sources can be in different demographics and cultures, and if they don’t have a centralized, standard process for data collection and annotation, that can affect the uniformity of the dataset.
Some other common non-uniformities observed in datasets are unit non-uniformity, date format non-uniformity, and label non-uniformity. Scatter plots across various attributes can give you a quick visual representation, and you can easily identify some non-uniformities before deploying a dataset to an algorithm.
Key Action: Uniformity across the dataset can be achieved through planning and defining each parameter in advance. Creating standard operating procedures for data collection, defining detailed and proper guidelines for annotation, preparing a list of all possible labels in advance, and having a clear understanding of use cases can help you acquire a uniform dataset.
AI model training is a continuous process. It is an evolving process where we are regularly training the AI model on new parameters. The world is constantly changing, and to keep pace with the market and its needs, we have to make sure we continuously evaluate our model and its performance. Based on these findings and other market research, we have to train our model.

We have to keep evaluating how users are interacting with our AI model. Is the model working the way we want it to work with even new users? If not, then we have to collect new datasets for every inconsistency in output and train our model on them.
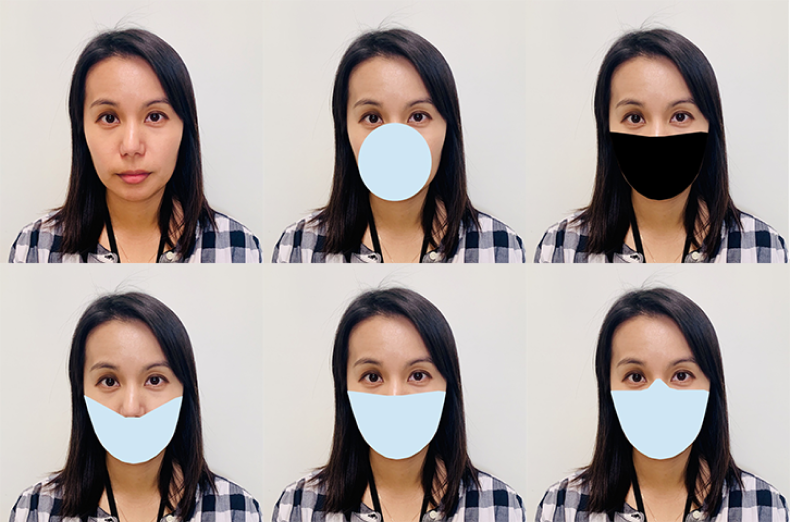
A recent study after the COVID pandemic on facial recognition uncovers the fact that facial recognition models created before the pandemic are generally performing less accurately for users who have their masks on. They tested 89 of the best commercial facial recognition models, and it resulted in a 5% to 50% error in matching the picture of a person without a mask with a picture of a person with a digitally applied mask.
So, in such cases where the market has changed or the way users interact with AI algorithms has changed, we have to train the model for new circumstances and make it compatible with the new generation of users. Apple did the same. It is claimed that iPhone 12 and later devices can now enable users to unlock their phones even while wearing their mask.
Key Action: Continuous improvement and market research are keys. During training, we must ensure that the dataset is not too old and contains all of the most recent data. Too old data might be irrelevant to the model. End-user personas and data directly from the end user can give you great confidence about the performance of an AI model.
After such an elaborate discussion on the characteristics of quality datasets and how they affect the performance of AI models, we must agree that dataset creation is a very expertise-driven task. You cannot just source data from anywhere and train the AI model. Such a model will serve no purpose. We must be confident about the data we are feeding into our AI model. The model's performance will be determined by the quality of the data.
In a nutshell, a quality dataset contains only useful parameters and data for all possible circumstances and is uniformly diverse for all possible user profiles.
People, process, and tools are some of the most influential parameters defining the quality of the dataset, which eventually defines the performance of the AI model.
The quality of the dataset starts with the people associated with it. It could be data providers or annotators. People’s attributes, like what expertise they have, what training they received, and their profiles, affect the dataset's quality to a great extent.
While collecting data, we have to make sure that we are onboarding and collecting data from a diverse community. For example, for building the Gujarati (India) ASR model, we have to collect speech data from different age groups, genders, and accents to make sure the model serves its purpose to the fullest.
The same is true for annotation: skilled and trained annotators can improve the dataset's quality. It is seen that when annotating for autonomous vehicles, real drivers holding a driver's license from any particular demography annotate an image dataset from that particular demography better than people who are not actual drivers. We can assume the same for the healthcare domain: an expert person can annotate or label healthcare images very well compared to others.
In the entire AI dataset procurement ecosystem, the contribution of humans-in-the-loop is enormous. AI communities like ours can help you leverage the potential of trained people in data collection and annotation to scale your AI process.
Data collection and annotation is a critical aspect of any AI project and should not be treated as a one-time event. Instead, it must be approached as a systematic and time-proven process. Without a defined process, it can be challenging to achieve the required standards of data quality and accuracy.
Effective data collection and annotation requires a clear understanding of the objectives, methods, and parameters of the dataset. A well-defined process allows for progress tracking, evaluation, and the flexibility to adapt to new methods as needed. Additionally, a robust process instills confidence in stakeholders and promotes collaboration and communication.
Our team has extensive experience working with real-life AI solutions for leading tech companies. We have developed a comprehensive process for data collection and annotation that has proven successful in various projects. Our process is not just a set of instructions, but a collection of our experiences and best practices.
Reducing the overall time spent while collecting data and annotating should be our goal while working on any AI solution. Accurately built tools can help you to a great extent.

For example, our Speech Data Collection mobile app, Yugo, allows us to onboard people from around the world and collect speech data, including scripted prompts and unscripted conversations, in the desired format along with required metadata. Using Yugo takes so much burden off us, and we can eventually deliver more accurate data in less time.
So, with that being discussed, we understand that the success of an AI project depends on three key elements: people, processes, and tools.
We strive to constantly innovate and improve our tools to make the data collection and annotation process seamless and efficient.
Our team's extensive experience working with leading tech companies on a variety of technologies, including computer vision, automatic speech recognition, optical character recognition, natural language processing, and machine translation, gives us the expertise and confidence to consistently deliver high-quality datasets.
Our pre-labeled dataset can assist you in scaling your AI process.
Our global crowd community from over 50 countries can help you collect unbiased datasets and annotate them for your specific AI use case.
Our state-of-the-art tools allow you to leverage structured datasets in the shortest time possible.
No matter where you are in your AI development process, our data experts are available to provide unbiased advice and assistance. Reach out to us for a spam-free consultation and let us help you achieve your AI goals.
